Scope
- Use Case
- Run a specific job within a job chain in a number of parallel instances, i.e. split a job for parallel processing. Each instance is executed on a different Agent.
- The use case is intended for execution of the same job within a job chain in parallel instances, not for parallel execution of different jobs.
- We assume am application for end of day processing that creates balance statements for a larger number of accounts. The application is installed on a number of servers each equiped with an Agent. The processing is splitted in a way that each instance of the application processes a chunk of accounts. The chunk size is calculated from the available Agents, not just from configured Agents.
- A similar use case is explained with the How to split and sync a dynamic number of job instances in a job chain article, however, this use case is about using a different Agent for each parallel process instead of running parallel processes on the same Master or Agent.
- Synchronize jobs after parallel processing.
- Run a specific job within a job chain in a number of parallel instances, i.e. split a job for parallel processing. Each instance is executed on a different Agent.
- Solution Outline
- The number of parallel job instances is dynamically determined from the number of Agents that are available to run the application.
- A number of orders is created for a specific job that would be executed in parallel on different Agents. The number of orders corresponds to the number of Agents and each order is parameterized to process a chunk of accounts.
- Finally the parallel job instances are synchronized for further processing.
- References
Solution
- Download parallel_job_instances_with_agents.zip
- Extract the archive to a folder
./config/liveof your JobScheduler installation. - The archive will extract the files to a folder
parallel_job_instances_with_agents. - You can store the sample files to a any folder as you like, the solution does not make use of specific folder names or job names.
Pattern
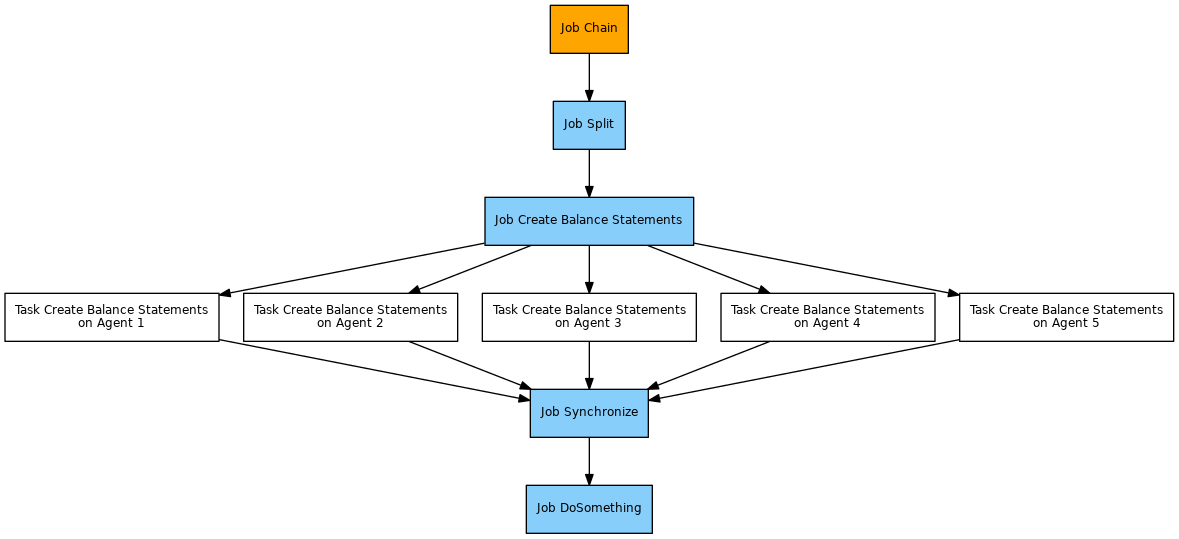
Implementation
Components
- The
end_of_day_splitjob reads the process class configuration that is assigned to its successor job which is thecreate_balance_statementsjob. It creates the number of orders that corresponds to the number of Agents.- Each order is added the following parameters:
number_of_orders: the number of orders that have been created.<job_chain_name>_required_orders: the number of orders that theend_of_day_syncjob waits for. This includes the value of thenumber_of_ordersparameter incremented by 1 for the main order. The prefix is made up of the name of the job chain to allow parallel use of this job with a number of job chains.
- The orders are assigned the state that is associated with the next job node, the
create_balance_statementsjob node, i.e. the orders will be executed starting with that state. - The orders are assigned the end state that is associated with the
end_of_day_syncjob.
- Each order is added the following parameters:
- The
create_balance_statementsjob is configured for a maximum number of 10 parallel tasks via the attribute<job tasks="10">. It could be configured for any number of parallel tasks. - The
end_of_day_syncjob is used to synchronize splitted orders and is provided by the Sync JITL Job with the Java classcom.sos.jitl.sync.JobSchedulerSynchronizeJobChainsJSAdapterClass. This job is used without parameters. - The
end_of_dayprocess class configures a number of Agents. - Hint: to re-use the
end_of_day_splitjob you can- store the job to some central folder and reference the job in individual job chains.
- move the JavaScript code of the job to some central location and use a corresponding
<include>element for individual job scripts.
Explanations
- Line 5: the
sync_state_nameparameter is used when creating child orders to specify the end state of child orders. - Line 15-37: the code is about parameter checking
- Line 39-70: the name of the process class is extracted from the successor job which is the
create_balance_statementsjob. As process classes can be referenced by absolute or relative paths the code calculates the absolute path and creates local variables for the directory, name and path of the process class. - Line 72-86: the code queries the JobScheduler Master to show the source of the process class. The answer is provided in XML format and is parsed accordingly. The xPath query in line 81 selects the Agent URLs from the process class.
- Line 88-127: each Agent URL that is extracted from the process class configuration is checked for an available Agent. This information is subsequently used to calculate the
min_accountandmax_accountparameters. - Line 98: executes a REST request to the JobScheduler Agent.
- The REST client library ships with JobScheduler and is explained with the How to implement a client for REST web services article.
- The REST interface for JobScheduler Master and Agents is explained with the JOC Cockpit - REST Web Service article.
- The technical documentation of the REST interface is available from the web site JOC Cockpit REST Web Services Technical Documentation (RAML Specification)
- Line 129-147: implements some arbitrary logic how to create chunks from the
min_accountandmax_accountparameters. The idea is to split the range into chunks that corresponds to the number of available Agents, however, any other logic could apply. - Line 149-161: for each Agent found from the process class an order is created and is parameterized with the respective chunk of accounts.
- Line 172-174: the main order is moved to the
end_of_day_syncjob node and async_session_idparameter is added that allows theend_of_day_syncjob to be used in parallel for a number of main orders.
Explanations
- Line 1: the job is assigned the
end_of_dayprocess class, see below configuration. - Line 5-7: the job includes an arbitrary implementation to create balance statements.
- For the sake of this sample the job simply uses some
echocommands. - The job uses the built-in environment variables
SCHEDULER_HOSTandSCHEDULER_HTTP_PORTto display the host and port of the Agent that the job is executed for. - The job displays parameters for the range of accounts that should be processed from the
SCHEDULER_PARAM_MIN_ACCOUNTandSCHEDULER_PARAM_MAX_ACCOUNTenvironment variables.
- For the sake of this sample the job simply uses some
- The job is implemented for Windows. For Unix environments use the
$SCHEDULER_HOSTinstead of%SCHEDULER_HOST%syntax to reference environment variables.
Explanations
- Line 3: the process class defines an Active Cluster with round-robin scheduling by use of the
select="next"attribute: each task for an order gets executed on the next Agent. - Line 4-6: the process class specifies a number of Agents that are addressed by the http or https protocol. If one of the Agents is not available then this is considered by the
end_of_day_splitjob when calculating chungs of work for thecreate_balance_statementsjob. - The process class is assigned to the job
create_balance_statements, see above job configuration.
Explanations
- Line 3-4: the order includes the parameters that specify the range of accounts for which balance statements are created.
- LIne 6: any order configuration, e.g. run-time rule, can be added.
Usage
- Start the
end_of_dayorder for theend_of_dayjob chain by use of JOC Cockpit. - Consider the processing that would
- split the execution into 3 subsequent orders that run for the
create_balance_statementsjob each on a different Agent. Should one of the Agents not be available then the number of orders is reduced and the chunk size is calculated accordingly. - move the current order to the
end_of_day_syncjob node.
- split the execution into 3 subsequent orders that run for the
- The splitted orders for the
create_balance_statementsjob will arrive in theend_of_day_syncjob node and will wait for all orders to be completed. With all splitted orders being completed the processing will continue.