Introduction
The JS7 Controller, Agents and JOC Cockpit make use of Unicode. When files are created or used then UTF-8 encoding applies.
- Unicode support works across any supported JS7 - Platforms.
- Limitations have to be considered in mixed environments that include Windows operating systems that ship without Unicode support and use a two byte subset UTF-16 LE.
JOC Cockpit requires the JS7 - Database to support UTF-8 encoding in order to store objects that hold such characters.
- For UTF-8 a single character stored to a JS7 database table requires 1 to 4 bytes.
- For example, NVARCHAR(10) specifies a column width of 10 characters that can consume 40 bytes.
The JDBC Drivers in use have to support Unicode.
JOC Cockpit
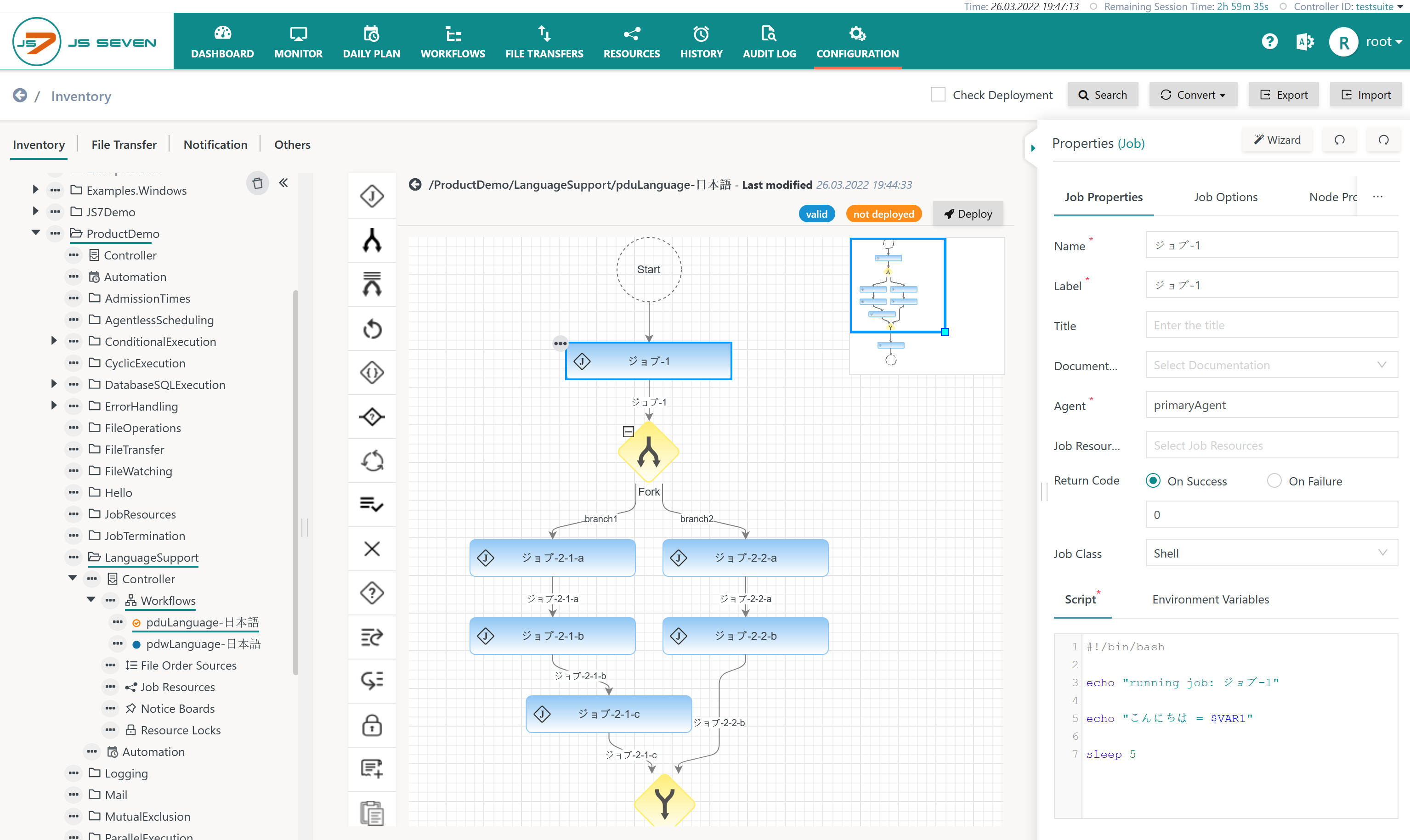
When designing workflows with the Configuration -> Inventory view users can make use of any Unicode characters within the scope of JS7 - Object Naming Rules.
- Download workflow for Unix (upload .json): pduLanguage-日本語.workflow.json
- Download workflow for Windows (upload .json): pdwLanguage-日本語.workflow.json
Configuration View
The Configuration -> Inventory view allows object names and job scripts to be specified using Unicode characters:
Workflows View
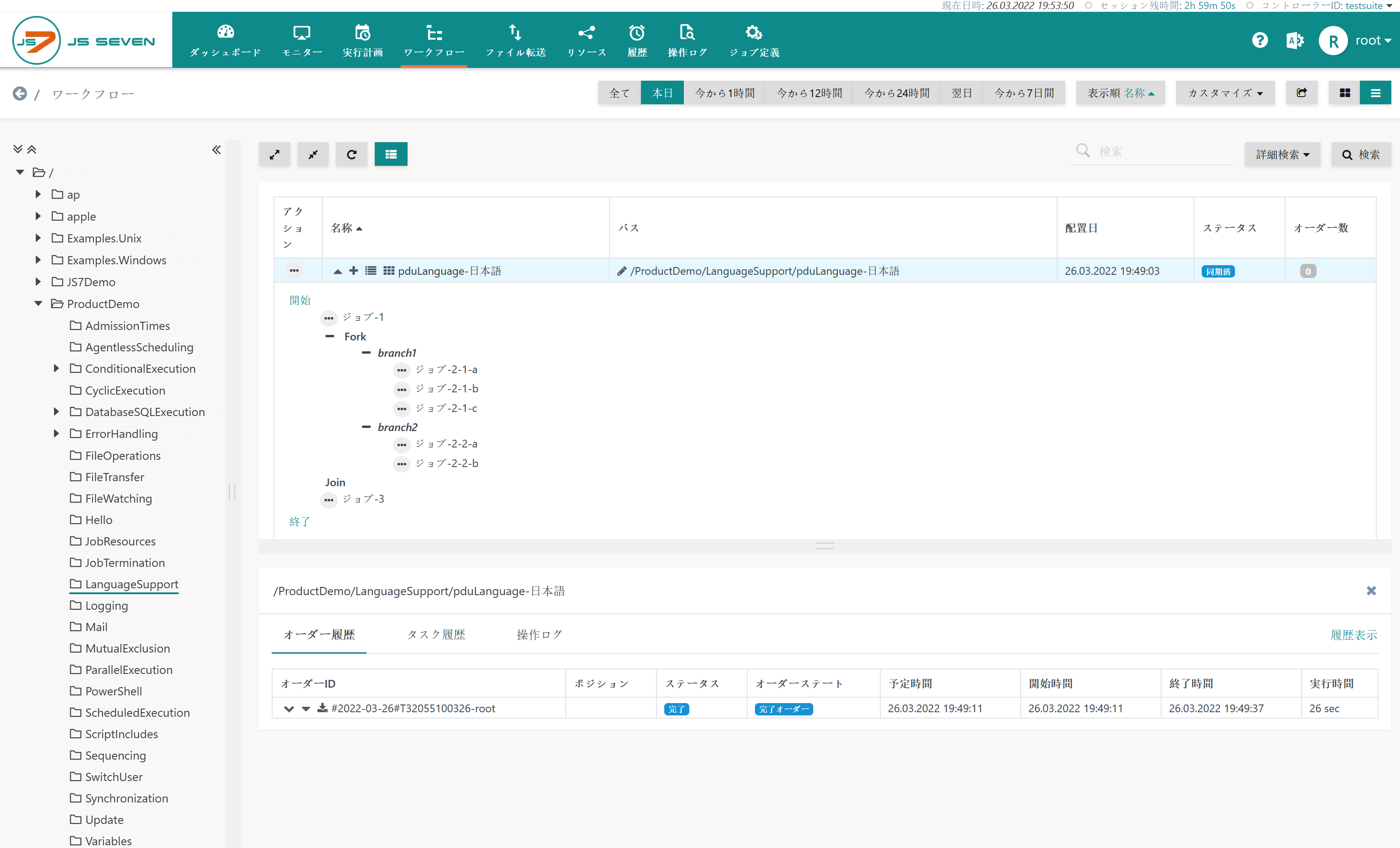
The Workflows view displays workflows using Unicode characters accordingly:
- The example below makes use of Japanese object names.
- In addition, the JOC Cockpit interface language has been switched to Japanese by use of JS7 - Profiles - Preferences.
Log View
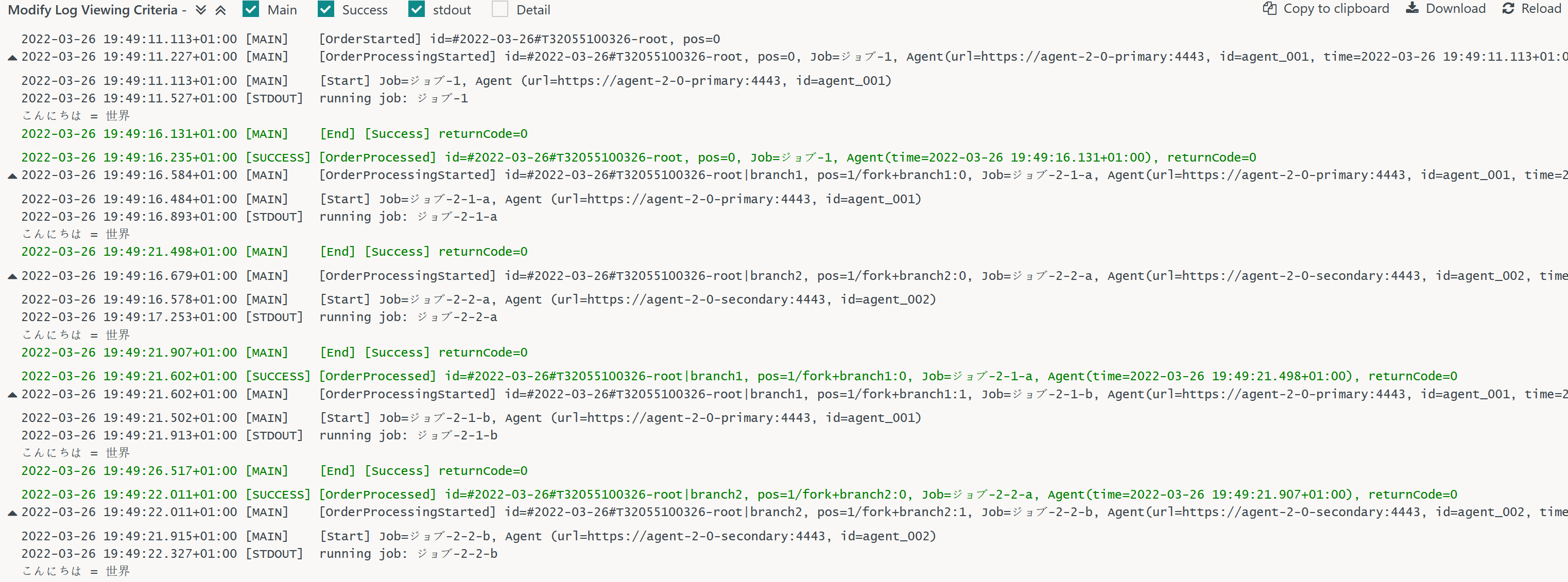
The Log view window displays output of jobs and instructions.
- Output is partly created from the JOC Cockpit and is qualified with markers such as [MAIN], [SUCCESS], [DETAIL].
- Output is partly created from job scripts executed with an OS shell. Such output is marked as [STDOUT] and [STDERR].
Explanation:
- Output from Unix Operating Systems
- Unix Operating Systems ship with built-in support for Unicode and UTF-8 encoding.
- Output from Windows Operating Systems
- Windows does not offer Unicode. Instead the OS ships with different code pages preinstalled depending on the location in which the OS is used.
- Some experimental Unicode support is available starting from Windows 10, however, as most Windows programs are not aware of Unicode there can be side-effects.
- Therefore the encoding of output created by jobs depends on the code page in use for the Windows OS which an Agent is operated on.
Controller
The Controller does not read or write files related to execution of workflows and jobs. The Controller reads configuration files and writes component log files only.
- Configuration files use UTF-8 encoding.
- Component log files are created with UTF-8 encoding.
Agent
Agents use an OS shell to execute jobs scripts. Agents collect output of jobs that is available from the stdout and stderr channels.
- For Unix environments the OS creates output in UTF-8 encoding.
- For Windows environments the OS makes use of a code page to encode output.
Use with Windows Code Pages
The Agent makes use of the code page that is active for the computer the Agent is operated on.
- In Asia code page 65001 or specific code pages such as 932 for Japan are frequently used.
- In Western Europe code page 850 is frequently used.
FEATURE AVAILABILITY STARTING FROM RELEASE 2.3.0
Supported Code Pages
The Agent automatically detects and makes use of the following code pages:
Specifying the Code Page
The Agent detects and makes use of the code page used by the Windows OS
- for code pages from the above list,
- for code pages that are prefixed with
cp#orCP#with # being the number of the code page.
Users can enforce use of a supported code page by adding a setting to the Agent's JS7_AGENT_CONFIG_DIR/agent.conf configuration file such as:
Setting to specify the code page from the agent.conf file
js7.job.execution.encoding = "UTF-8"
Explanation:
- This setting specifies the MIME type not the numeric code page identifier, for example
UTF-8instead of65001. - Users should be aware that modifying the Agent's code page will not modify the code page of the underlying OS shell.
- OS commands will continue to encode output with the OS code page.
Examples for Windows Code Pages
The following examples explain use of Windows code pages.
Download (upload .json): pdLanguageSupportSwitchCodePage.workflow.json
Workflow Jobs: ハローワールドジョブ
Example for the first job in the workflow
@echo off echo running job: %JOB_NAME% echo 日本語 echo var1=日本語 >> %JS7_RETURN_VALUES% echo last_job_name=%JOB_NAME% >> %JS7_RETURN_VALUES% chcp
Explanation:
- The first job is assigned an environment variable
JOB_NAMEfrom a built-in global variable like this:
- Line 3: The output of the
JOB_NAMEenvironment variable can be scrambled if the server does not use a compatible code page, see chapter Log View. - Line 4: The job displays Unicode characters that have been directly added to the job script.
- Line 6, 7: The job creates two variables for use with later jobs:
var1: the variable directly holds Unicode characters.last_job_name: the variable holds the name of the current job.
- Line 9: The job displays the current code page.
Example for the second job in the workflow
@cmd.exe /K chcp 65001 <nul set /p "echo=running job %JOB_NAME%" <nul set /p "echo=last job name: %LAST_JOB_NAME%" <nul set /p "echo=value of variable var1: %VAR1%" <nul set /p "echo=日本語" chcp
Explanation:
- Line 1: The job script creates a new shell and switches to a Unicode code page.
- Line 3: The output created for the current job name is readable from the log view as the code page now includes Unicode support.
- Line 4: The output of the
last_job_namevariable will be scrambled if the predecessor job created this variable from a non-matching code page. - Line 5, 6:: The output is readable in the log.
Log View

Overview
Content Tools