Introduction
Use of a JS7 - JOC Cockpit Cluster provides high availability and is a feature that is subject to the JS7 - License.
- Fail-over is an automated operation that occurs when the Primary JOC Cockpit is aborted or killed. Fail-over is applied in case of normal and abnormal termination.
- Switch-over is an operation that is caused by user intervention in JOC Cockpit or by use of the JS7 - REST Web Service API. The procedure includes normal termination of an Active JOC Cockpit Instance.
JOC Cockpit plays a limited role when it comes to high availability:
- All workflows and jobs are executed with the Controller and Agents only. Orders are started and executed independently of the JOC Cockpit once they have been submitted by the JS7 - Daily Plan.
- In the event of the JOC Cockpit becoming unavailable:
- users cannot monitor and control the status of Controllers and Agents,
- users cannot deploy scheduling objects to Controllers and Agents,
- users cannot access the JS7 - History for execution results and log output of orders and tasks.
For command line references see the JS7 - JOC Cockpit - Command Line Operation article.
Cluster Roles
The JS7 documentation frequently contains references to the Primary JOC Cockpit Instance and any number of Secondary JOC Cockpit Instances. These names suggest that one JOC Cockpit Instance is primarily used and other instances are used for backup purposes.
- The terms Active JOC Cockpit Instance and the Standby JOC Cockpit Instances are often more significant, regardless of whether it is the Primary or a Secondary JOC Cockpit Instance that is active.
- The JOC Cockpit implements an active-passive cluster, however, the term passive is misleading as the Standby JOC Cockpit Instances are not necessarily passive:
- Users can login to a Standby JOC Cockpit Instance and perform any of the operations that are available from the Active JOC Cockpit Instance.
- The following limitations apply to use of Standby JOC Cockpit Instances:
- The JS7 - Dashboard does not automatically update order states, history information and cluster status information. Such information is updated when navigating to the page.
- No running log is available for orders and tasks that are currently executed. In addition, no access to order logs and task logs is available for the time that an order is not completed.
- Any JOC Cockpit instances operated as a cluster use the same JS7 - Database.
- The database is used to synchronize cluster operations.
- Unavailability of the database prevents the JOC Cockpit cluster from working.
Cluster Operations
Cluster operations include an automated fail-over and a manual switch-over of the Active JOC Cockpit Instance.
Fail-over
Fail-over occurs when the Active JOC Cockpit Instance is terminated abnormally.
Fail-over can be invoked by the following actions:
- The Active JOC Cockpit Instance is killed, for example:
- on Unix with a SIGKILL signal corresponding to the command:
kill -9 - on Windows with the command:
taskkill /F
- on Unix with a SIGKILL signal corresponding to the command:
- The operating system crashes.
Fail-over happens within a period of time that depends on the number of orders that have been started but have not yet completed. The minimum duration of a fail-over is 30s and can last for 2-3 minutes if thousands of active orders are in place.
Switch-over
Switch-over occurs exclusively when invoked by user intervention.
Switch-over can be invoked by the following actions:
- In the JS7 - Dashboard the user performs the operation:
- Standby JOC Cockpit Instance action menu: Switch-over
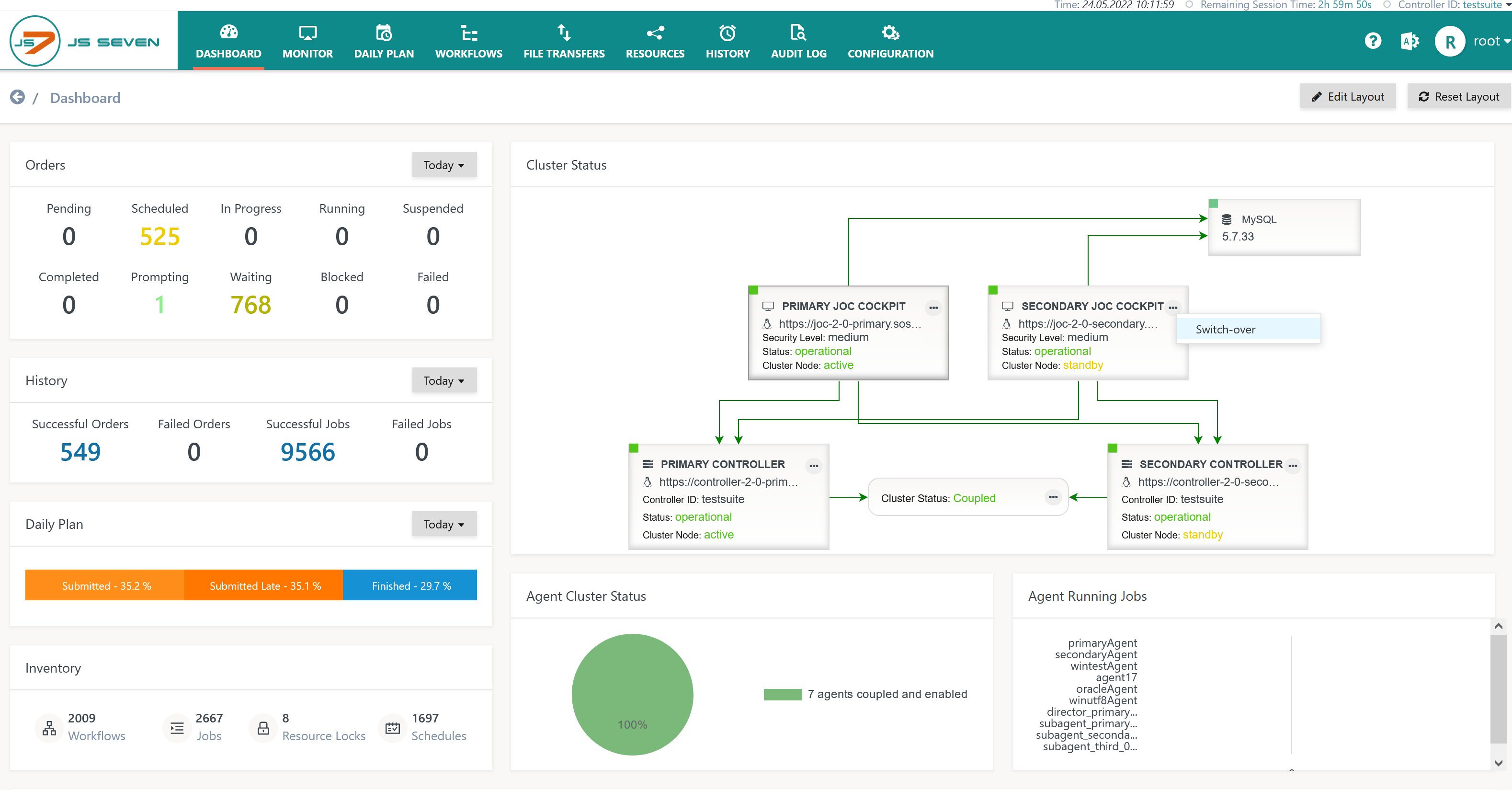
- Standby JOC Cockpit Instance action menu: Switch-over
- the Active JOC Cockpit Instance is stopped normally from the command line:
jetty.sh | .cmd stop
- the operating system is shut down and
systemd/init.dor a Windows Service are in place to stop the JOC Cockpit normally.
Switch-over happens within a similar period of time as fail-over.
Further Resources
- JS7 - JOC Cockpit Cluster
- JS7 - Initial Operation for JOC Cockpit Cluster
- JS7 - JOC Cockpit - Command Line Operation
Overview
Content Tools