UNDER PROGRESS
Question
How do I start a job chain on arrival of a file?
Solution
Download
- Download the attached archive:
- Windows operation system example FileWatching.zip
- Linux operating system example FileWatchingLinux.zip
- Unzip the archive to the
livefolder of your JobScheduler installation - Create inbound, success and error directories
- Adjust the configuration to your environment
Components
- A job chain that monitors the directory for incoming files
- One jobs that prints trigger File's Name on stdout.
Introduction
A job chains can be triggered by two type of Orders 1. time based Orders and 2. File Orders. A job chain can be configured to start on arrival of a file by using File Order Source.
A File Order Source require configured by minimum to parameters 1. Directory and 2. Regex, where Directory is the file system location where JobScheduler should watch for arrival of a file and Regex is the Regular Expression which should be matched with the filename to trigger the job chain. Most simple example of File Order Source is <file_order_source directory="c:\sandbox\outgoing" regex="^test.txt$"/>
How to configure File Order Source - job chain
To learn how to create a job chain, refer following article JobScheduler - Tutorial 2 - Editing a Simple Job with JOE.
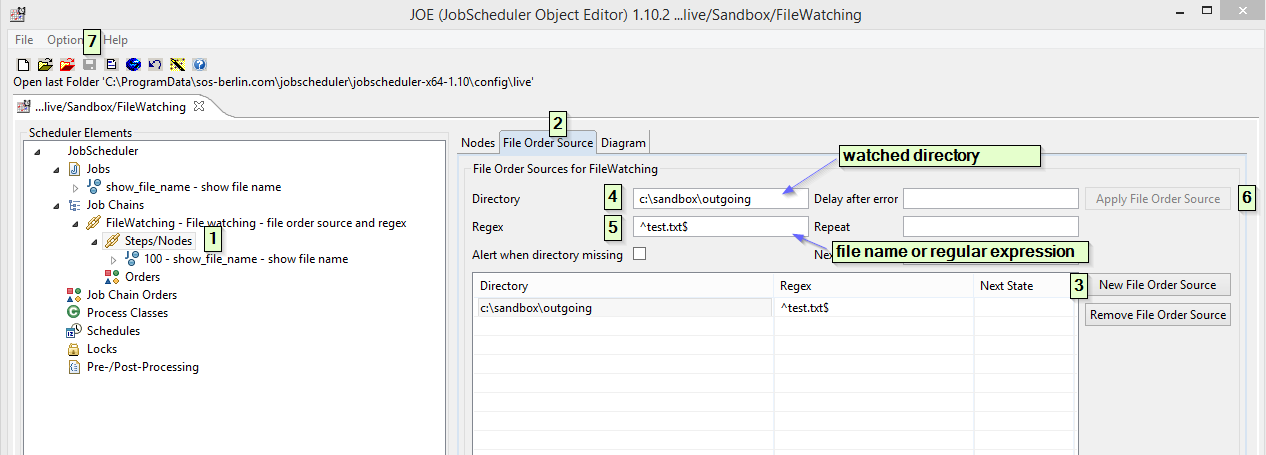
- Open your job chain in JOE (JobScheduler Object Editor), expand job chain's and click on
Steps/Nodes. - From right wondow pan select
File Order Sourcetab - Click on
New File Order Source, this will open a dialog to create a new File Order Source configuration. - Click in the text filed in front of
Directoryparameter, configure directory which should be watched for arrival of file e.g.c:\sandbox\outgoing - Click in the text field in-front of
Regexparameter, configure file name or Regular Expression e.g.^test.txt$. - Click
Apply File Order Sourcebutton to apply your configuration. - Click
Saveto save job chain
Example: job chain FileWatching - file order source
Following example is a Windows operation system FileWatching job chain, configured to start as soon as the file test.txt arrives in the directory c:\sandbox\outgoing. The File Order will be processed as normal order through job chain, one step to the next, until the Order reaches to end node of job chain. In this example there are two distinctive job chain end nodes, each one for success and error state of File Order processing.
<?xml version="1.0" encoding="ISO-8859-1"?>
<job_chain title="File watching - file order source and regex" name="FileWatching">
<file_order_source directory="c:\sandbox\outgoing" regex="^test.txt$"/>
<job_chain_node state="100" job="show_file_name" next_state="success" error_state="error"/>
<file_order_sink state="success" remove="yes"/>
<file_order_sink state="error" remove="yes"/>
</job_chain>
Example: job - show_file_name
By default JobScheduler creates few internal environment variables during the Order processing. All the JobScheduler environment variables are prefixed by SCHEDULER_PARAMS_ prefix. JobScheduler stores the trigger file's path in environment variable SCHEDULER_PARAM_SCHEDULER_FILE_PATH In the following job example JobScheduler's inbuilt environment variable SCHEDULER_PARAM_SCHEDULER_FILE_PATH will be used to print file name on the stdout.
<?xml version="1.0" encoding="ISO-8859-1"?>
<job order="yes" stop_on_error="no" title="show file name" name="show_file_name">
<script language="shell">
<![CDATA[
@echo %SCHEDULER_JOB_NAME% : job starting
@echo .
@echo %SCHEDULER_JOB_NAME% :Start for file [ %SCHEDULER_PARAM_SCHEDULER_FILE_PATH% ].....
@echo .
@echo File Name : %SCHEDULER_PARAM_SCHEDULER_FILE_PATH%
@echo %SCHEDULER_JOB_NAME% :End for file [ %SCHEDULER_PARAM_SCHEDULER_FILE_PATH% ] .....
]]>
</script>
<run_time />
</job>
How to configure File Order Sink - job chain
Every File Order is associated with a file on file system, this file was used as trigger to start the job chain. JobScheduler offers two options to handle files associated with a File Order, Once a File Order reaches to the end success/error node of job chain, file associated with it either can be remove or move to a location.
Remove File
A file_order_sink node can be configured to remove file after processing e.g.( <file_order_sink state="success" remove="yes"/> ). File associated with the File Order will be deleted from file system location configured in the directory parameter.
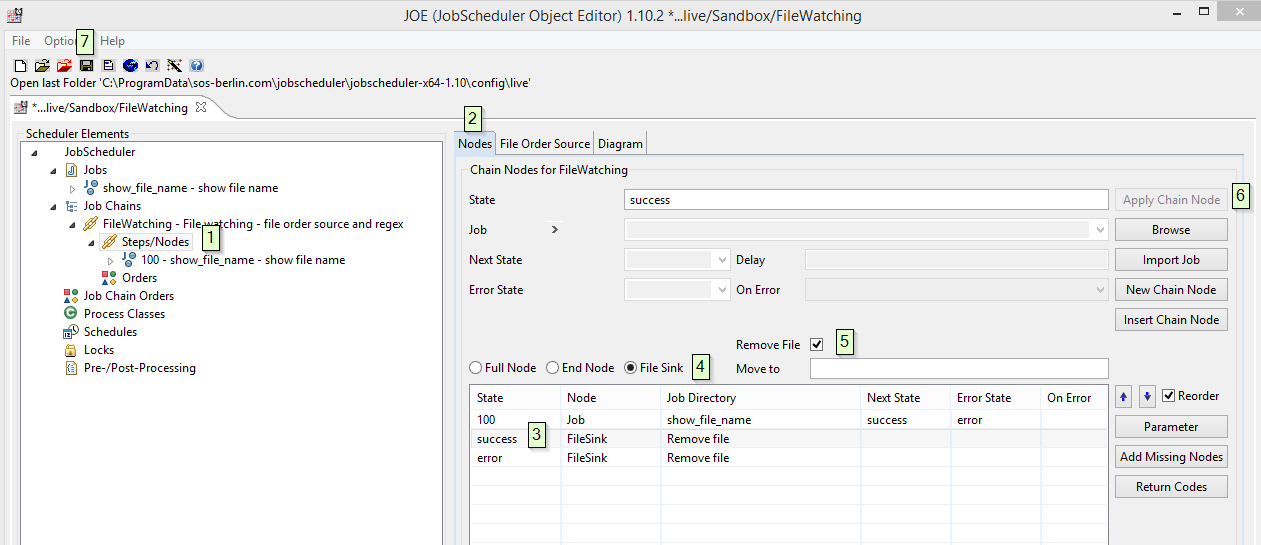
- Open your job chain in JOE (JobScheduler Object Editor), expand job chain's and click on
Steps/Nodes. - From right wondow pan select
Nodestab - Click on state
success, this will enable the dialog to configure FIle Order Sink for success state - Select radio option File Sink
- Select check box
Remove Fileto enable delete file after successful processing. - Click
Apply Chain Nodebutton to apply your configuration. - Click
Saveto save job chain - Repeat steps 3 to 7 for error state too.
Move File
A file_order_sink node can be configured to move file after processing to another directory e.g. (<file_order_sink state="success" remove="no" move_to="c:\sandbox\success"/>). File associated with the File Order will be moved from file system location configured in the directory parameter to the location configured in the move_to parameter.
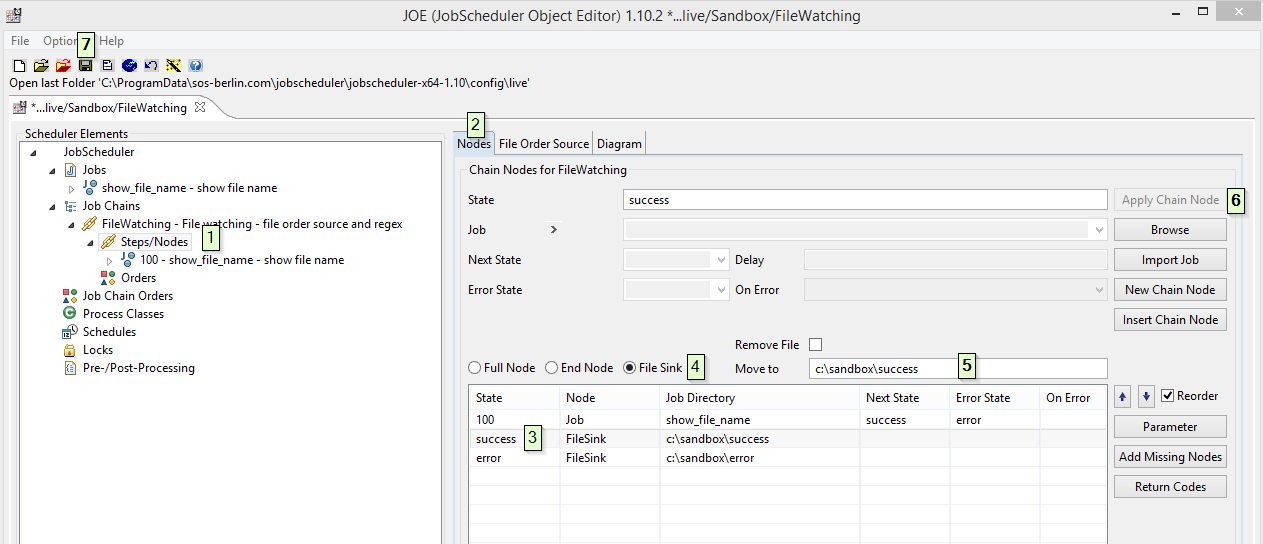
- Open your job chain in JOE (JobScheduler Object Editor), expand job chain's and click on
Steps/Nodes. - From right wondow pan select
Nodestab - Click on state
success, this will enable the dialog to configure FIle Order Sink for success state - Select radio option File Sink
- Click in the text field in-front of
Move toparameter, configure directory location where file should be move after successful processing e.g.c:\sandbox\success. - Click
Apply Chain Nodebutton to apply your configuration. - Click
Saveto save job chain - Repeat steps 3 to 7 for error state too.
Operation
To trigger the FileWatching job chain, create a file test.txt in directory c:\sandbox\success. As soon as file is created, JobScheduler will start the FileWatching job chain.
See also
- How to monitor a folder for more than one file name pattern
- How to monitor incoming files, check the file for a string and parameterize subsequent jobs
- How to prevent an error when a file order directory is missing