Introduction
Consider the situation where files with different categories (i.e. files with similar characteristics such as type, source, or similar) can be processed in parallel but all the files of any one category have to be processed sequentially.
For example, the centralised data processing of a company receives stock movement reports from subsidiaries at regular intervals. Whilst the reports from different subsidiaries can be processed simultaneously, the reports from each subsidiary have to be processed sequentially.
The 'Best Practice' Solution
Our recommended approach for this situation would be:
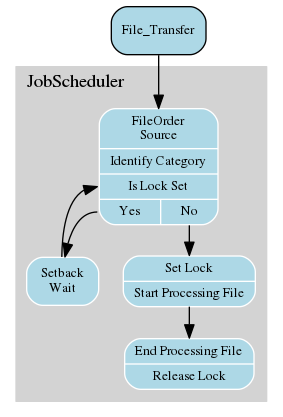
- The most important feature of this solution is that it only requires one job chain and one set of jobs to separate the processing of different categories of files, thereby simplifying maintenance of the jobs and job chain.
- Use a single load_file File Order Source directory to which all files are delivered.
- JobScheduler would use regular expressions to identify the files arriving in this directory on the basis of their names, timestamps or file extensions and forward them for processing accordingly.
JobScheduler would then set a lock for the subsidiary whose file is being processed to prevent further files from this subsidiary being processed as long as processing continues.Should a 'new' file from this subsidiary arrive whilst its predecessor is being processed, the job 'receiving' the new file will be set back by JobScheduler as long as the lock for the subsidiary is set.
- This lock would be released by JobScheduler once processing of the 'first' file has been completed.
- The job 'receiving' the new file will now be able to forward the new file for processing.
The Solution in Detail
JobScheduler starts as soon as a file matching a regular expression is found in the directory.
This directory is set in the "File Order Sources" area in the "Steps/Nodes" view of the "load_files" job chain as shown in the screenshot below:
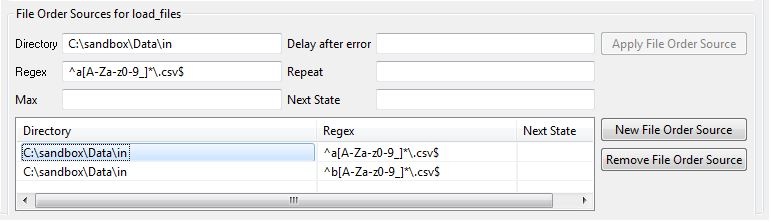
- JobScheduler's
aquire_lockjob matches files using regular expressions and determines the file's category - for example, Berlin or Munich.The regular expressions are also defined in the "File Order Sources" area shown in the screenshot. Note that for simplicity the regular expressions match the prefixes "a" and "b" in the file names and not directly "Berlin" or "Munich". The
aquire_lockjob uses a Rhino JavaScript to try to aquire the lock and either wait if the lock is not available or proceed to the next node if it is.
This script is listed below:function spooler_process() { try { var parameters = spooler_task.order().params(); var filePath = "" + String(parameters.value("scheduler_file_path")); spooler_log.info( " scheduler_file_path : " + filePath ); var param1 = "" + String(parameters.value("param1")); spooler_log.info( " param1 : " + param1 ); var fileParts = filePath.split("\\"); var fileName = fileParts[fileParts.length-1]; spooler_log.info( "fileName : " + fileName ); if(fileName.match("^a[A-Za-z0-9_]*\.csv$")) { var lockName = "BERLIN_PROC"; var lock_name = "BERLIN_PROC"; spooler_log.info( "File matched with berlin lock_name : "+ lockName ); } if(fileName.match("^b[A-Za-z0-9_]*\.csv$")) { var lockName = "MUNICH_PROC"; spooler_log.info( "File matched with berlin lock_name : "+ lockName ); } spooler_task.order().params().set_value("file_spec",fileName); spooler_task.order().params().set_value("lock_name",lockName); if (!spooler.locks().lock_or_null( lockName )) { var lock = spooler.locks().create_lock(); lock.set_name( lockName ); spooler.locks().add_lock( lock ); if (spooler_task.try_hold_lock( lockName )) { return true; } else { spooler_task.call_me_again_when_locks_available(); } } else { spooler_task.order().setback(); spooler_log.info( " lock is already aquired , lock_name : "+ lockName +" , setback , will retry after some time"); } return true; } catch (e) { spooler_log.warn("error occurred : " + String(e)); return false; } }
- Once
aquire_lockfinds the matching category it will try to set a semaphore (flag) using JobScheduler's inbuilt LOCK mechanism - Only one instance of each LOCK is allowed as can be seen in
Max Non Exclusiveparameter shown in the screenshot of JobScheduler's JOE interface below: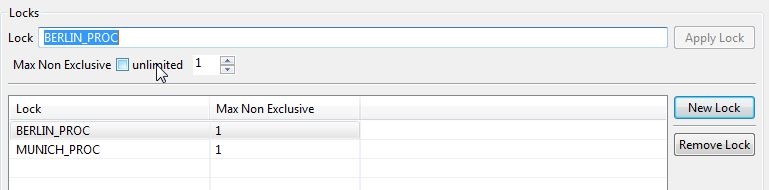
- Once a LOCK has been assigned to a file from a category (either Berlin or Munich), all subsequent files for this category have to wait with a setback until the LOCK has been released.
The same mechanism will be repeated for files from other categories. As long as a file of any given category is not being processed and therefore the corresponding LOCK not been set, the way will be free for the file from the other category to be allowed to be processed.
This can be seen in the following screenshot of the JOC interface showing the progression of file orders along the
load_filesjob chain:
- Once process is finished depending upon success or error, JobScheduler will move the file from the in folder to either the done (on success) or failed (on error) folders.
- After moving the input file to the correct target directory by JobScheduler, the
release_lockjob will be called, which will remove the lock/semaphore from JobScheduler and allow the next file from the same category to be processed.
The following screenshot from the JobScheduler's JOE interface shows the nodes in the load_files job chain and their related states:
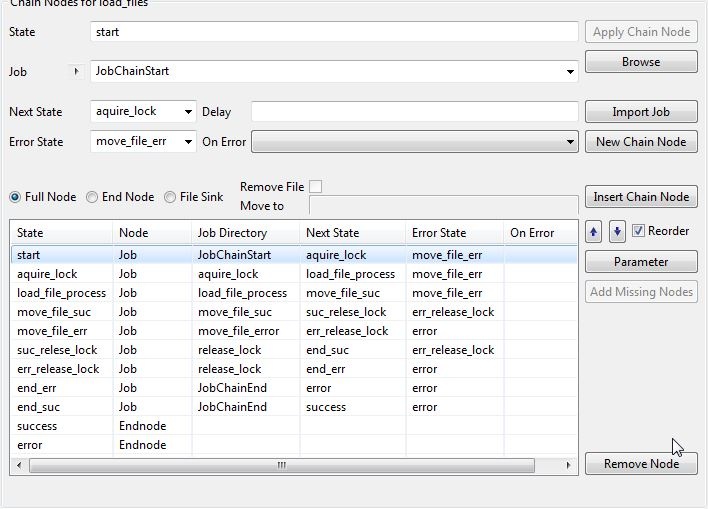
The release_lock job uses a similar Rhino JavaScript to the aquire_lock as can be seen in the following listing:
function spooler_process() {
try {
var parameters = spooler_task.order().params();
var filePath = "" + String(parameters.value("scheduler_file_path"));
spooler_log.info( " scheduler_file_path : " + filePath );
var lockName = "" + String(parameters.value( "lock_name" ));
spooler_log.info( " lock_name : " + lockName );
if (spooler.locks().lock_or_null( lockName )) {
spooler.locks().lock( lockName ).remove();
}
return true;
} catch (e) {
spooler_log.warn("error occurred: " + String(e));
return false;
}
}
A job to force
release_lockis also required for the situation that the processing of a job fails without the corresponding lock being released.The script for this job to release the 'Berlin' lock would look something like:
function spooler_process() {
try {
var lock_name = "BERLIN_PROC";
spooler.locks().lock(lock_name).remove();
return true;
} catch (e) {
spooler_log.warn("error occurred: " + String(e));
return false;
}
}
Limitations of this solution
The limitation of this approach will become apparent if more than one file should arrive from a subsidary at once.
This is because there is no guarantee that files arriving together will be processed in any given order. This situation typically occurs after an unplanned loss of a file transfer connection. After the connection has been restored, there is a) no guarantee that the files arriving as a batch will be written to the file systen in a particular order b) no way for JobScheduler to know how many files will arrive as a batch.
One solution here would be to wait until a steady state in the incoming directory has been reached (i.e. no new file has been added and the size of all files remains constant over a suitable period of time) before starting to identify files. JobScheduler could then order files according to their names before forwarding them for processing.
The downside of this second approach is that it brings a delay in starting processing with it, due to the need wait to check whether all members of a batch of files has arrived by checking for a steady state.
Solution Demo
A demonstration of this solution is available for download from:
Demo Installation
- Unpack the zip file to a local directory
Copy the 'SQLLoaderProc' folder to your JobScheduler 'live' folder.
TODO - ADD LINK TO DOKU
Copy the 'Data' folder to the a suitable local location.
The default location for this folder, which is specified in the configurations in the demo jobs, is:
C:\sandbox- The 'load_files' File Order Source directories in the
load_files.job_chain.xmljob chain object - the 'source_file' and 'target_file' paths specified as parameters in the
move_file_suc.job.xmlandmove_file_error.job.xmlobjects
- The 'load_files' File Order Source directories in the
Note that the following paths have to be modified if the location of the 'Data' folder is changed:
Running the demo
- Just copy files from the 'Data/__test-files' folder to the 'in' folder:
- JobScheduler will automatically start processing within a few seconds
- Once processing has been completed the file(s) added to the 'in' folder will be moved to the 'done' or 'failed' folders, depending on whether processing was successful or not.
- DO NOT attempt to start an order for the job chain. This will only cause an error in the
aquire_lockjob.
How does the Demo Work?
BoxTitle=The demo 'load_files' job chain |
BoxContent 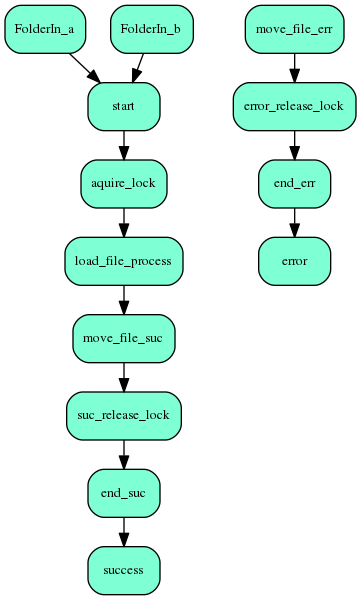 |
The demo job chain ('load_files') is shown in the diagram to the right.
See also
- Our Using locks FAQ.
- The Locks section in the JobScheduler reference documentation.
- Example for YADE to check files for completeness by steady state