Scope
- Use Case
- Run parts of a job chain in parallel, where parallel processing is already being carried out.
- Solution Outline
- Two standard JITL Jobs are provided for this:
- JobSchedulerJobChainSplitter
- splits an incoming order into multiple orders that are run in parallel through a job chain within a range of predefined job chain nodes.
- JobSchedulerJoinOrders
- joins the orders that have previously been split in a job chain node, i.e. this job forces any split orders to complete to this job chain node before processing continues.
- References
- Availability
Solution
- Download nested_parallel_execution.zip
- Extract the archive to a folder
./config/live of your JobScheduler Master installation. - The archive will extract the files to a folder
nested_parallel_execution. - You can save the sample files in any folder as you like, the solution does not require the use of specific folder names. Job names can be freely chosen, with the exception of JITL jobs - which here are JobChainSplitter and join.
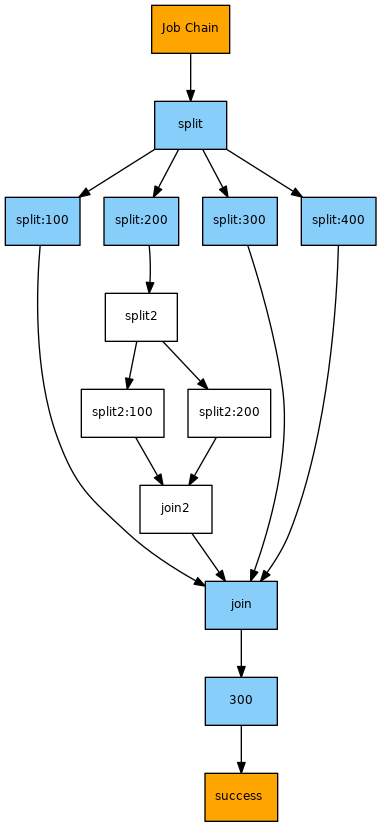
Job Chain Pattern
Implementation
Components
- Neither the Job Chain and Jobs jobA to jobD provided in the current example are not specific to this solution. The jobs represent simple shell scripts.
- The two
split jobs (split and split2) are instances of the Splitter JITL Job and use the Java class com.sos.jitl.splitter.JobChainSplitterJSAdapterClass.- The job is used with the following parameters:
state_names: a list of semicolon separated Job Node states which split Orders are added to. An individual Order is created for each entry in this list.- The state names correspond to the states that the respective job nodes are associated with in the job chain definition.
- State names for the first node of each of the job chain segments that are executed in parallel should be prefixed with the name of the state of the
split_partitions job and a colon. This should be followed by a unique descriptor, usually name of the job associated with the state but this is not mandatory. This convention is necessary to ensure correct display of dependencies in JOE and the JOC Cockpit. For example, state of one of the nested job chain segments in the example used in this article is: - Note that the naming convention for state names for the first node of each parallel job chain segment does not have to be followed for subsequent nodes in the job chain segment (See the example in the How to split and join jobs in a job chain article.)
- The state names corresponding to the first nodes in each parallel job chain segment are specified in the
state_names parameter. For example, the split2 instance of the JobChainSplitter job has the value:
split_partitions:job3;split_partitions:job4
join_state_name: this parameter specifies the name of the state for the join node corresponding to the splitter node. For example the value specified for the split2 instance of the JobChainSplitter job is:
- Any number of jobs can follow the jobs that are referenced by the
state_names parameter.
- The job
job_chain1.join_partitions is used to join up split orders and is provided by the Join Orders JITL Job with the Java class com.sos.jitl.join.JobSchedulerJoinOrdersJSAdapterClass.- The recommended naming convention for this job uses the job chain name as a prefix: due to the nature of this job to join up across all job chains that are running in the system and that make use of the same join job name you should prefix the job name with the job chain name if you want this job to be limited to work for the current job chain.
- This job is used without parameters.
Usage
- Start the main Order (named start in this example) for the Job Chain using JOC. In the current example this will immediately start processing the split Job.
- Each split job generates a new Order for each split part of the Job Chain. The main Order will then jump to the join node corresponding to the split node and wait (in the suspended state) for the processing of all the parallel chain segments to be completed. The name of this node is specified in the
join_state_name: parameter described above. In the current example, the start Order will wait at the join node until the split:100, join, split:300 and split:400 jobs have successfully completed being processed.
{"serverDuration": 137, "requestCorrelationId": "6b3787927763e348"}