Introduction
- A splitter job is needed to run two or more jobs in parallel.
- The splitter job parameter state_names contains the state names of the parallel running jobs.
- Usually every splitter job ends with a sync job.
Copy splitter job - sos/jitl/JobChainSplitter.job.xml.
JITL-149 - Getting issue details... STATUS
- Within JITL comes with JobScheduler a ready to use splitter job - sos/jitl/JobChainSplitter.job.xml.
- Add a new job node for a job chain in JOE and copy the JITL splitter job. Use the Browse button and navigate in the Live folder to /sos/jitl. Select the splitter job JobChainSplitter.job.xml.
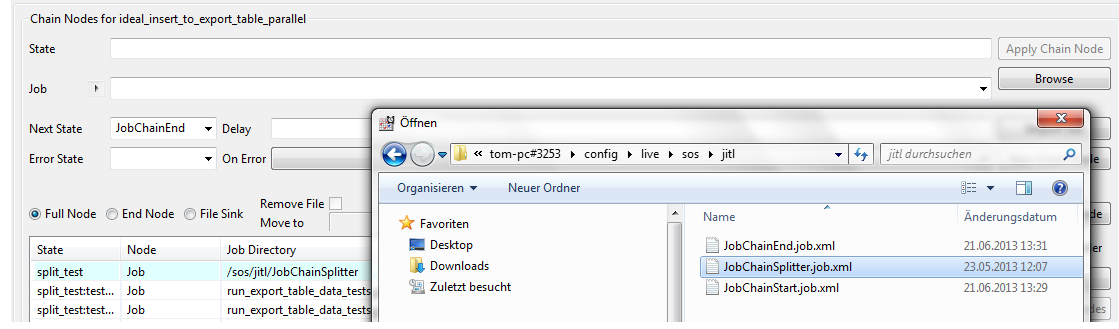
Splitter node
We recommend to begin the name of the splitter node with the string split e.g. split_partitions.
Parameter state_names
- Mark the splitter node in JOE in the menu Job Chains and click the button Parameter.
- Type state_names as parameter name.
- Provide all node names of the jobs to run in parallel with this splitter job in the field Value. Separate the node names by semicolon.
Parallel nodes
We recommend that you use the following syntax for the names of job nodes that are processed in parallel: "splitter job node name" ":" "job name".
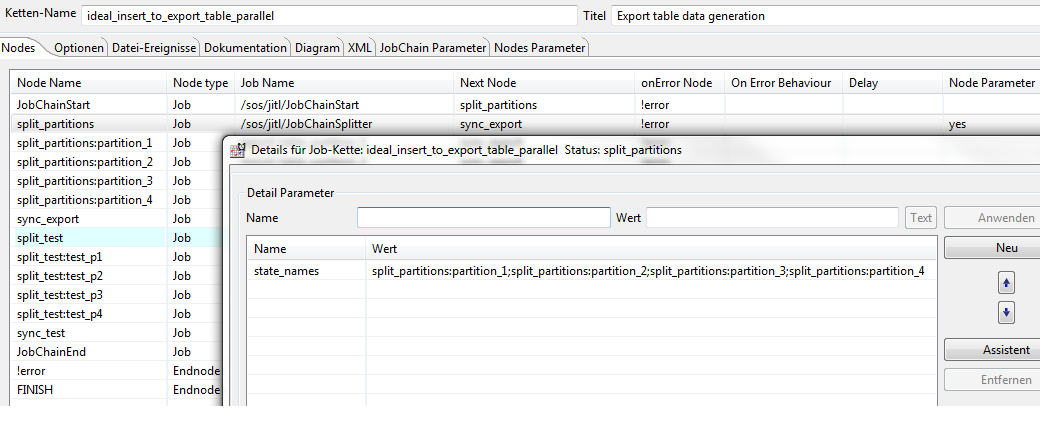
End every splitter job with a sync job
The Splitter defines a context for the sync job. With this a global sync job can be used simultaneously in different job chains. The context is defined by the name of the job chain (parameter job_chain_name2synchronize) and the name of the node of the sync job (parameter job_chain_state2synchronize). The value for the node of the sync job is the value of the parameter sync_state_name. If there is no parameter sync_state_name, the value of the next_state of the current state is used.
It is also possible to define a sync job with a unique name to have a sync job for each job chain.
Unique name for sync job
Example: ideal_insert_to_export_table_parallel.sync_partitions
Change Management References
See also