Example: Synchronization of multiple Job Chains (cross-over)
In this example we have three job chains. Two of them contain steps that run in parallel. Processing of both these job chains is also synchronized in two ways:
- Each chain contains a synchronization node that only allows processing to continue to the next node when processing in the other chain has also reached its corresponding synchronization point.
- Both chains have to end successfully before the third chain will start.
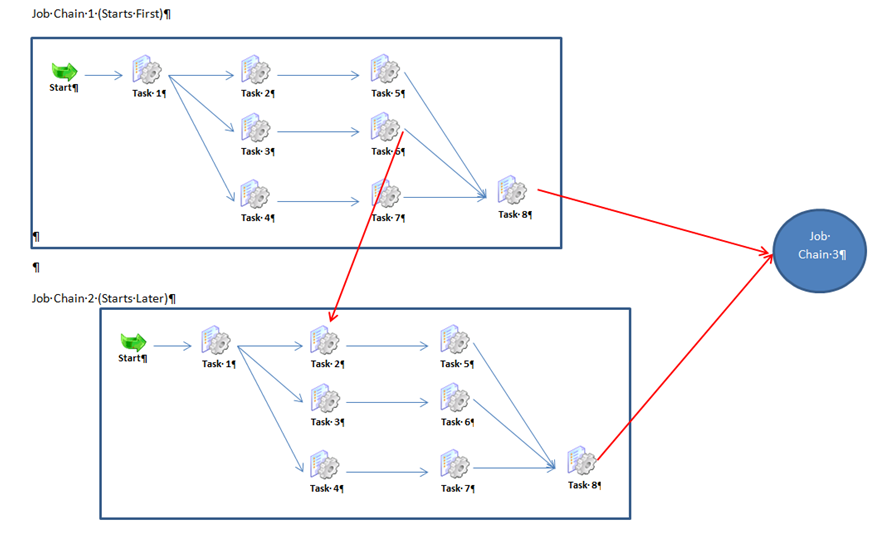
This requirement was implemented as follows:
- JobChain1: JobChain-Interlink-1 with the jobs JobInterlink-1-<n> , <nh1. 1-8
- JobChain2: JobChain-Interlink-2 with the jobs JobInterlink-2-<n> , <n>1-8
- JobChain3: JobChain-Interlink-3 with job JobInterlink-3-1
- There is another job chain, which generate an order for each job chain by using the Command statement.
Generating the job chains of the requirement
Parallel execution within the job chains
Parallel execution is realized by Split jobs and Sync jobs - as it is described in the Parallel Execution in a job chain example.
The /sos/jitl/JobChainSplitter job in the ./live/sos/jitl directory is used for the splitter job, which is part of the JobScheduler download.
The com.sos.jitl.sync.JobSchedulerSynchronizeJobChainsJSAdapterClass JAVA class is used in the sync jobs.
Synchronization of the JobInterlink1 and JobInterlink2 job chains
According to request the job jobInterlink-2-2 starts only when the job jobInterlink-1-6 is successfully completed. Therefore we need a sync state after the job jobInterlink-1-6 and before the job jobInterlink-2-2 with the identical state name Sync_Interlink1_Interlink2.
As soon as the job jobInterlink-1-6 has finished, the synchronization is activated, the subsequent job jobInterlink-2-2 starts running and the branch of the parallel execution including job jobInterlink-1-6 comes to its sync state.
Synchronization before the start of the third job chain
The third job chain is to be started only when both predecessor job chains JobInterlink1 and JobInterlink2 are finished successfully. This dependency is also realized with a sync job. We define the sync job Sync_Interlink12_Interlink3 and inserted the node after the jobs jobInterlink-1-8 and jobInterlink-2-8 in the predecessor job chains and before jobInterlink-3-1 in the job chain which is to be started.
Every synchronization node has its own sync job!
Schema of the Job Chains in JOE
The job chains were realized by using the JobScheduler job editor JOE.

Generating orders with a starter job chain
Each of the three job chains requires an order to start. In this example we have a starter job chain with one job for each chain, with this job generating the order.
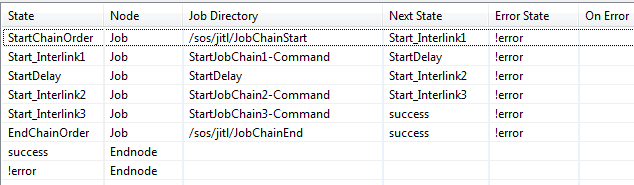
In these jobs the order command is used as paramter with the name of the job chain. If necessary the path under the LIVE folder could be included.
<?xml version="1.0" encoding="ISO-8859-1"?>
<job title="Start JobChain via Command" order="yes">
<params />
<script language="shell">
<![CDATA[ echo ========== Generate Order for JobChain-Interlink-1 ========== exit 0 ]]>
</script>
<run_time />
<commands on_exit_code="error"/>
<commands on_exit_code="success">
<order job_chain="/Schulung/Aufgabe_verlinkte_Ketten/JobChain-Interlink-1" replace="yes"/>
</commands>
</job>
Another way to generate an order would be to use a script. For example:
<?xml version="1.0" encoding="ISO-8859-1"?>
<job stop_on_error="no" order="yes" title="Order für JobChain Interlink-1 erstellen (script)">
<script language="javax.script:rhino">
<![CDATA[
function spooler_process()
\{
var order = spooler.create_order();
spooler.job_chain( '/Schulung/Aufgabe_verlinkte_Ketten/JobChain-Interlink-1' ).add_order( order );
return true;
\}
]]>
</script>
<run_time />
</job>
Best practices
Standard nodes for Start and End
We recommend that you use our /sos/jitl/JobChainStart start job as the first node in every job chain and our /sos/jitl/JobChainEnd'end job as the last full node.
Give each sync job a unique name
Give each sync job a unique name by using the name of the job chain in which the sync job is included in the name of the sync job.
For example:
- Sync_Interlink1_Interlink2
Follow our convention for node naming:
Splitter node
We recommend that the node name of a splitter job starts with the character string split - for example Split_Interlink1.
This syntax allows the diagram algorithm in JOE- next version - to draw job chain diagrams and correctly display the nodes that directly follow on from the splitter. It is necessary to use this type of job name syntax for the algorithm as the syntax used by JobScheduler does not recognize predecessor relationships (only successors).
Parallel nodes
We recommend that you use the following syntax for the names of job nodes that are processed in parallel:
"splitter job node name" ":" "job name".
In the example above, one of the first nodes would then have the name split_Interlink1:Job-1-2.
This syntax allows the diagram algorithm in JOE - planned for release with JobScheduler version 1.7 - to draw job chain diagrams and correctly display the nodes that directly follow on from the splitter. It is necessary to use this type of job name syntax for the algorithm as the syntax used by JobScheduler does not recognize predecessor relationships (only successors).
Job nodes
As far as possible, the names of job nodes should identical to the job names (poss. without the folder name). If a job is used more than once in a job chain, then the node name can be uniquely specified using a letter or number as a suffix.
Error nodes
The name of the error node should either contain the job name or be identical with it. This means that in the event of an processing error in the job chain, it is possible to see immediately in JOC the point in the job chain where the abnormal termination occured. In addition, the name should start with an "!" (an exclamation point) - like !error. The JobScheduler Information Dashboard JID is using it to mark an error status in red.
See also
- Documentation of Job JobSchedulerSynchronizeJobChains.
- More examples for sync jobs see here: JobScheduler_FAQ
Downloads
This example can be downloaded here: synchronization_jobchains.zip.