h1. setting up a splitter job
- A splitter job is needed to run two or more jobs in parallel.
- The splitter job parameter state_names contains the state names of the parallel running jobs.
- Usualy every splitter job ends whith a sync job.
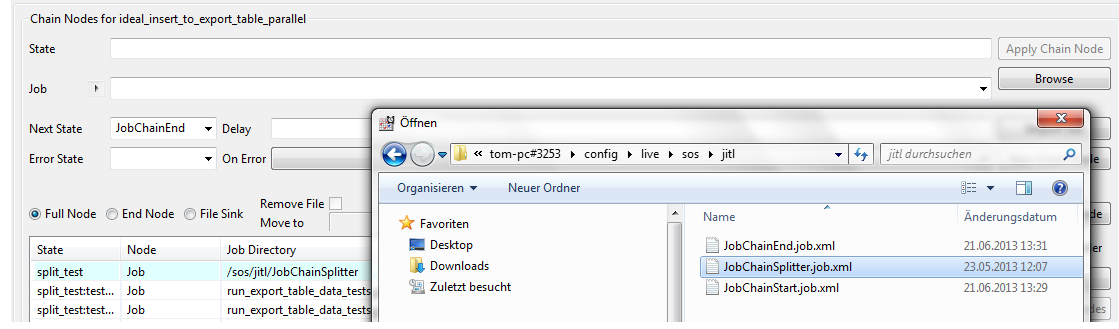
copy splitter job - sos/jitl/JobChainSplitter.job.xml.
- Within JITL comes with JobScheduler a ready to use splitter job - sos/jitl/JobChainSplitter.job.xml.
- Add a new job node for a job chain in JOE and copy the JITL splitter job. Use the Browse button und navigate in the Live folder to /sos/jitl. Select the splitter job JobChainSplitter.job.xml.
splitter node
We recomend to begin the name of the splitter node with the string split e.g. split_partitions (see Best Practices - Splitter nodes).
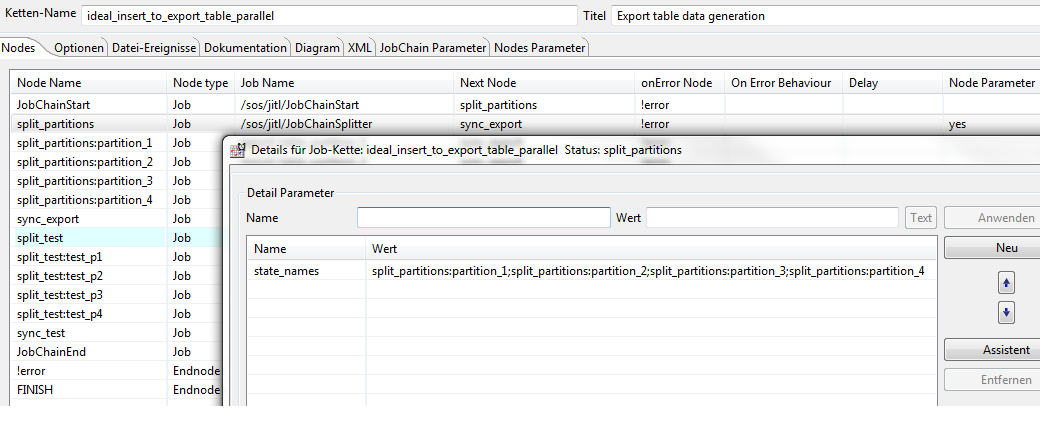
Parameter state_names
- Mark the splitter node in JOE in the menue Job Chains and click the button Parameter.
- Type state_names as parameter name.
- Provide all node names of the jobs to run in parallel with this splitter job in the field Value. Separate the node names by semicolon.
Parallel nodes
We recommend that you use the following syntax for the names of job nodes that are processed in parallel: "splitter job node name" ":" "job name". (Best_Practices).
Jeden Splitter-Job mit einem Sync-Job beenden
Jeder Splitter-Job muss mit einem Sync-Job beendet werden(siehe Sync-Job erstellen).
- Der Sync-Job für einen Splitter-Job muss innerhalb einer JobScheduler-Instanz eindeutig sein.
Der Sync-Job arbeitet mit Parametern aus 'seinem' Splitter-Job. Würde ein Sync-Job für verschiedene Splitter-Jobs verwendet werden, könnten die Parameter aus den Splitter-Jobs falsch interpretiert werden. Das würde zu kaum nachvollziehbaren Ergebnissen führen und sollte unbedingt vermieden werden.
Eindeutiger Name für Sync-Job
Um den Sync-Job eindeutig zu definieren empfehlen wir, den Namen der Jobkette, in welcher der Sync-Job verwendet wird, als Präfix in dem Job-Namen des Sync-Jobs zu verwenden.
Beispiel: ideal_insert_to_export_table_parallel.sync_partitions