Introduction
This article gives an overview of the JobScheduler Monitoring Interface.The Monitoring Interface provides an efficient means for monitoring JobScheduler objects such as Jobs, Job Chains and Orders and forwarding notifications to System Monitors such as Nagios®. This solution is available with JobScheduler General Availability Release 1.8 onwards.
The most important features of this solution are:
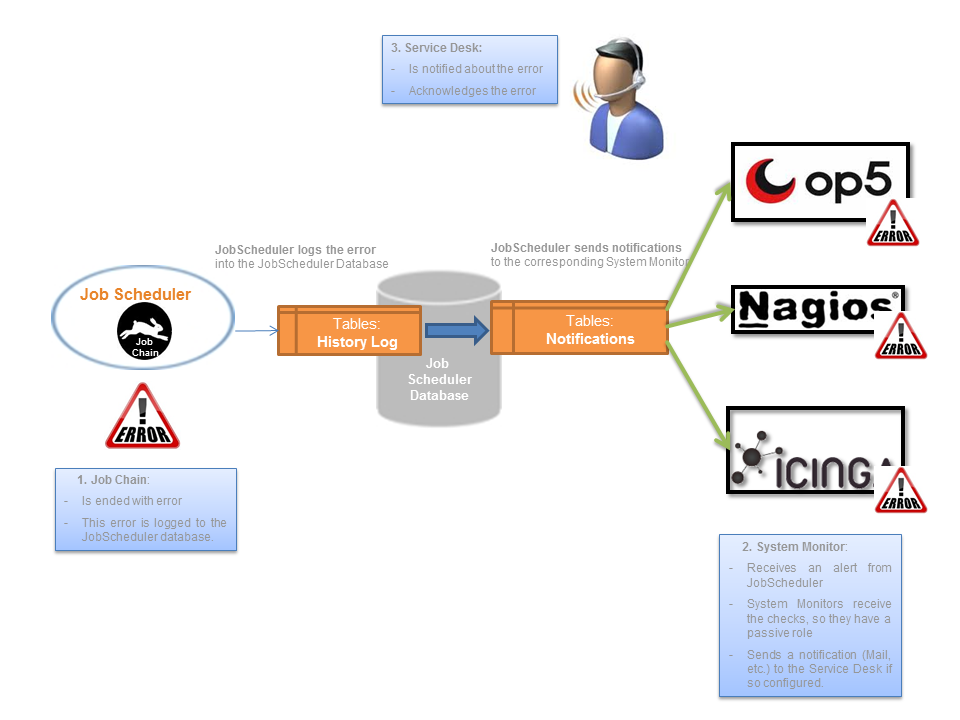
- JobScheduler: carries out a two step process around the interface:
- Detecting errors and other events: A Job running at regular intervals - typically every 2 minutes - analyses the History Log information recorded by the JobScheduler in the database. This job is configured not only to filter but also to analyze the log information for the Job Scheduler objects being monitored. The information noted is typically whether tasks have been successfully completed or whether errors or warnings have been logged. This job then writes this information in a separate Notifications database table.
JITL-166 - Getting issue details... STATUS - Sending alerts: A second Job is responsible for sending the alerts to the relevant System Monitor. This job is also run at regular intervals, analyzing the Notifications database tables. It then carries out a predefined action for each item it finds in the table. Typical actions would be informing a particular monitor that a particular type of event has occurred, such as the successful completion of an order, a job ending in error or whether error recovery is being attempted.
- Detecting errors and other events: A Job running at regular intervals - typically every 2 minutes - analyses the History Log information recorded by the JobScheduler in the database. This job is configured not only to filter but also to analyze the log information for the Job Scheduler objects being monitored. The information noted is typically whether tasks have been successfully completed or whether errors or warnings have been logged. This job then writes this information in a separate Notifications database table.
- JobScheduler: The solution architecture allows analysis of the Log History of more than one JobScheduler using the database specified. It may also be configured to monitor more that one database.
- System Monitors: the JobScheduler is able to connect to more than one System Monitor at the same time.
Monitoring Definitions
The following definitions apply for the monitoring systems:
| Definition | Description |
|---|---|
| System Monitor | A System Monitor is an instrument to inform a Service Desk (e.g. 1st Level Support) about incidents in IT systems. It does not analyze incidents, but merely information about incidents, in order to be able to forward and scale this information. |
| Passive Checks | Passive Checks are sent remotely from an external host (from the point of view of the System Monitor) to the Monitor. Otherwise, checks that are carried out periodically by the System Monitor itself are called Active Checks. |
| Active Checks | Active Checks are initiated from the System Monitor server and are performed on a regular basis, e.g. every 5 minutes. They are intended for simple verification of availability of a daemon/service, they do not provide information at application level, e.g. on the execution status of jobs. Use of Active Checks is explained in How to perform active checks with a System Monitor such as Nagios/op5 |
| Alerting | An Alert is a message about an event. An Alert does not provide all the information about an event, but it informs about the existence of the event. An Alert can be either positive or negative. |
| Notification | The notification of a specific Alert. Notification will not be provided for every Alert, just the ones that are so configured will be notified. Notifications are therefore a subset of the Alerts and can also be either positive or negative. |
| Acknowledgment | Is the confirmation of an alert and it has the meaning that the alert has been seen and/or is known and that appropriate action is being taken. An acknowledgment is always manually executed. This means that there is always someone that has realized there is a Critical service and this person acknowledges the services (usually by the Service Desk or 1st Level Support). It is never an automatized step. |
Benefits
The benefits of the new solution are:
- Flexible implementation:
Changes to your existing JobScheduler configuration (Jobs, Job Chains, etc.) are not required to get this solution working. You add the Job Chains required for the monitoring but do not have to modify your current ones. - Monitor independence:
The whole architecture lies on the JobScheduler side and the solution is therefore independent of the monitor that the Alerts are sent to. The solution works for every monitor that can receive passive checks. - Workload-independent:
Processing of Jobs and Job Chains in JobScheduler is not affected or modified by the monitoring, neither from the point of view of performance nor that of stability. - Clearly defined information flow:
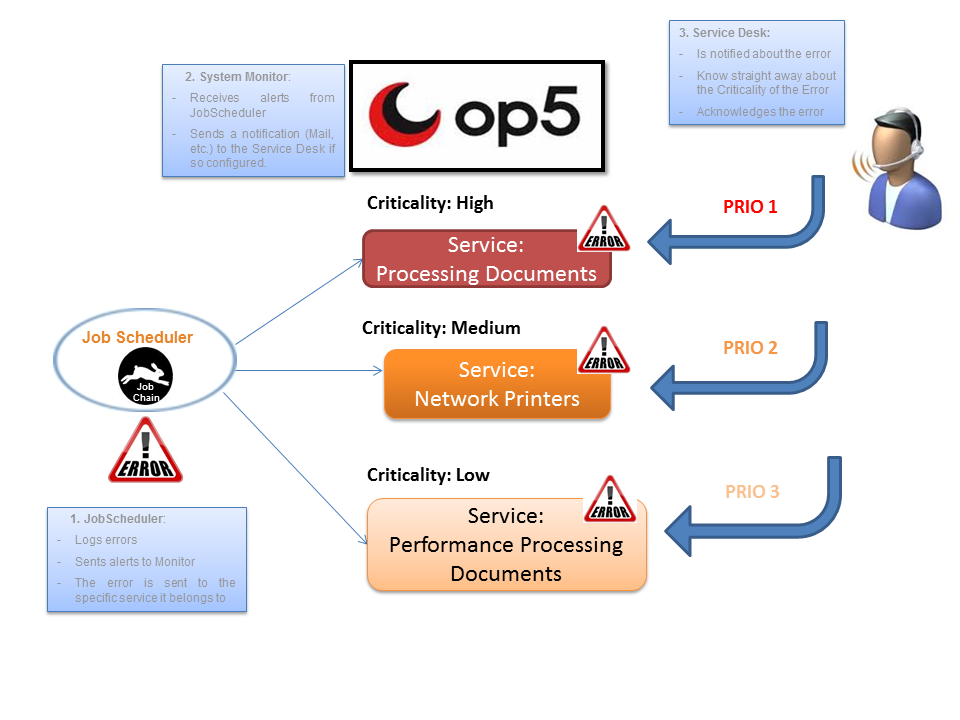
This solution allows the information to be made available to the System Monitors to be exactly configured. Detailed log information from monitored Job Chains can be sent as a Passive Check to the relevant Monitoring Service if required. - Error Prioritization
Errors of a critical nature are immediately recognized in the System Monitor. The JobScheduler has initially access to all the log information and can be configured to filter this information very exactly before forwarding it to the relevant System Monitor Service. This feature allows the Service Desk to be able to set priorities immediately when, for example, recovering errors: it is unlikely that a performance error would be given the same priority as an error in document processing. This feature is illustrated in the following diagram:
Functionality
| Functionality | Description |
|---|---|
| Job Chain and Order Monitoring | This solution allows Job Chains to be monitored by way of the Orders that trigger these Job Chains. |
| History Notifications | Not only can critical alerts be monitored, but also positive ones. The history of a specific service can be monitored to see exactly if a specific work-flow has been executed and what result it gave. |
| Performance measurement (Timer) | Timers can be used to measure the performance of Job Chains. These can be used to send a warning alert to a System Monitor if a Job Chain takes more that a predefined time to complete. |
| Acknowledgment | Acknowledgments sent in response to critical alerts sent out by a System Monitor can be used to add Orders to the JobScheduler, so that the JobScheduler does not send more notifications about a service to the System Monitor. |
Monitoring example - op5® Monitor
The following example illustrates use of the JobScheduler Monitoring interface with the op5® Monitor. In the example, three checks (in op5® Monitor they are called services) have been defined for the JobScheduler monitoring. Different Job Chains in JobScheduler can send notifications to the same check, so that it is not necessary to create checks for each individual Job Chain, which could become extremely complex. Instead, results have been grouped in three categories:
- JobScheduler Monitoring Errors: Job Chains that end with an error are sent to this service. The last error notification is shown in the column "STATUS INFORMATION".
- JobScheduler Monitoring Success: Job Chains that end with success, that is with a positive notification, are sent to the monitoring system. To be exact, the history of a specific Job Chain is monitored to see whether a specific work-flow has been executed or not. The last success notification is shown in the column "STATUS INFORMATION".
- JobScheduler Monitoring Performance: Here timers are used to measure the performance of a Job Chain. If a Job Chain takes too long to end, a warning alert will be sent to the System Monitor. The information about the expired timer is shown in the column "STATUS INFORMATION".

Change Management References
See also
- JobScheduler Monitoring Interface - Prerequisites and Installation
- JobScheduler Monitoring Interface - Configuration and Use Cases
- JobScheduler Monitoring Interface - XML Configuration