Serialisation
Consider the situation where a large number of similar data records are to be processed one after the other. A typical example here would be credit card transactions from a cash terminal or a retail checkout. A standard procedure used to speed up processing of such data records is to split up each item into its constitutent parts and process each part separately. With financial transactions, each data record is usually made up of a header, body and footer, with the header and footer being of fixed length and the length of the body varying with the number of items in the transaction.
Here we have a situation with a combination of parallel and serial processing as shown in the following diagram.
Processing Diagram

It should be clear that in order to ensure that processing of the different parallel steps does not get out of step it is necessary to introduce some sort of synchronization. One approach would be to use split and sync jobs as described in Example for parallel execution in a job chain. It is however important to ensure that the processing of data records is clearly seperated from each another. This clearly seperated serial processing of data is the subject of this FAQ.
In the solution described here, a lock is set each time processing of a data record is started. This lock is then released once the processing of all parts of the data record has been completed. The parallel processing steps themselves are treated seperately - a 'black-box' approach which increases the flexibility of use.
Note that with this approach JobScheduler locks are not quite used as intended - they are normally aquired by jobs (see our Locks FAQ). Instead they are used as a convenient method of setting a flag.
The Job Chain
The example job chain only illustrates the steps relevant to the lock, which take place before and after the parallel processing steps. These are represented schematically in the example job chain by two jobs, pre_proc_check and process_data. The pre_proc_check job represents the splitting up the data record into its constitutent parts and the process data job represents the parallel processing and bringing together of the parallel processing threads.
The example job chain is started by one of three file_order_sources, filtered by a regular expression. All three file_order_sources lead directly to the start node.
The success and !error nodes are file_order_sink nodes that are configured to remove the file_order_source files.
The job chain, as shown in JOE (JobScheduler Object Editor) looks like:
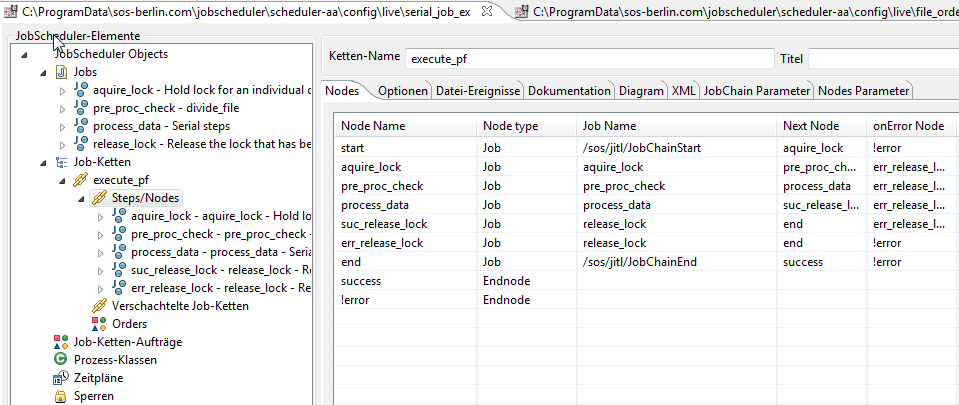
- The locks in this example are generated dynamically using the JobScheduler internal API and in the code examples presented here Rhino JavaScript is used.
- The lock is created (if it does not already exist) and set in the aquire_lock job and released in release_lock job.
- In the following chapters find the code used for each job.
The Jobs
Job Script: aquire_lock
function spooler_process() {
try {
if (!spooler.locks().lock_or_null('FILE_PROC')) {
var lock = spooler.locks().create_lock();
lock.set_name('FILE_PROC');
spooler.locks().add_lock( lock );
if (spooler_task.try_hold_lock('FILE_PROC')) {
return true;
} else {
spooler_task.call_me_again_when_locks_available();
}
} else {
spooler_task.order().setback();
}
return true;
} catch (e) {
spooler_log.warn("error occurred : " + String(e));
return false;
}
}
Job Script: release_lock
function spooler_process() {
try {
if (spooler.locks().lock_or_null('FILE_PROC')) {
spooler.locks().lock('FILE_PROC').remove();
}
return true;
} catch (e) {
spooler_log.warn("error occurred: " + String(e));
return false;
}
}
Related Downloads
Download the example files:
- serial_job_execution_with_locks.zip
Follow the instructions in the 'ReadMe_serial_job_execution_with_locks' file to install and use the example.
See also
- Best Practice for guidelines about creating job chains.
- Internal API Job Implementation Tutorial.
- The Rhino section of the JobScheduler API Reference documentation.
- How can I best get started with the JobScheduler Java API Reference Impl?
- The Locks section of the JobScheduler reference documentation]