General
The trend towards hosting enterprise applications such as Datawarehouses, Databases, Batch Applications, etc. in Clouds such as the Amazon AWS EC2 Instance is growing and JobScheduler is no exception. Recently we have had many customer queries regarding setting up JobScheduler in the Cloud.
JobScheduler can be setup as a single instance, as primary and backup instances or many JobScheduler instances together can be setup as JobScheduler cluster in a Cloud infrastructure.
System setup
JobScheduler can be installed in a Cloud Instance ( Amazon AWS EC2 Instance) with the usual JobScheduler installer i.e. command line/GUI as per a conventional OS.
Once JobScheduler has been installed and configured JobScheduler objects can be deployed to the Cloud JobScheduler instance as well.
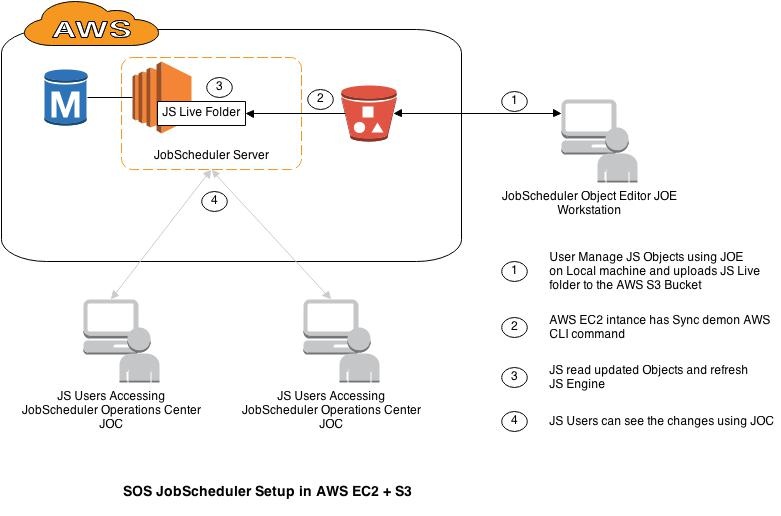
One of the interesting ways to deploy JobScheduler objects directly to Amazon AWS EC2 instance is to put the JobScheduler objects i.e. jobs, jobchains, orders etc into AWS an S3 Bucket and SYNC the S3 Bucket to the JobScheduler live folder.
1. User can manage JobScheduler Objects
User or group responsible to manage JobScheduler objects i.e. create/update Job/JobChain/Order etc can create XMLs using JOE (JobScheduler Object Editor) on their Desktops.
2. User uploads JobScheduler objects into AWS S3 Bucket
Once Objects are created, user can upload them using AWS S3's browser utility or any other widely available desktop AWS S3 sync utility.
There are many solutions available to mount AWS S3 as desktop drive or as local file system. User can choose any widely available tool as per their requirement.
3. AWS CLI Sync command download(Sync) JobScheduler Object from S3 Bucket to local Live folder
User can create simple demon script started with system startup on JobScheduler server and sync AWS S3 Bucket to local live folder.
To keep JobScheduler Objects for different development phases user can create different Buckets i.e. JobScheduler-DEV, JobScheduler-TST, JobScheduler-INT JobScheduler-PRD.
To deploy JobScheduler Objects from their respective Buckets, users can map DEV Bucket with DEV server and so on. One can use AWS IAM and Security groups to manage Rights on S3 Buckets and correct mapping with servers.
So, if someone tries to sync DEV JS objects on Prod server, AWS security group will prevent such action.
Example: simple AWS CLI sync command
test@js-eudebe-001:~> aws s3 sync s3://jobscheduler/jobscheduler-dev /app/jobscheduler/config/live
Please see more options here AWS CLI sync command documentation
4. JobScheduler reads changed/updated objects and refresh the JobScheduler engine
JobScheduler continuously monitors the Live folder for any change. As soon as JobScheduler finds any changes in objects i.e. Job/Jobchain/Order, JobScheduler updates the JobScheduler engine with changes i.e. Calendar, executable or any other condition. Changes are immateriality visible in the JOC (JobScheduler Operations Center) and JID (JobScheduler Information Dashboard).
5. JobScheduler users can see the the updated objects in JOC
6. Drawio XML file
- Drawio File: Drawio-JS-AWS-EC2-S3-Concept.xml http://www.sos-berlin.com/download/samples/Drawio-JS-AWS-EC2-S3-Concept.xml