Introduction
- The Controller Cluster brings high-availability including fail-over capabilities for the deployment of scheduling objects and for execution of workflows.
- Two Controller instances are operated on different servers to synchronize JS7 - Order State Transitions and log events.
- Automated fail-over guarantees high-availability and restart capability of a Controller Cluster (passive cluster).
- Use of the Controller Cluster is subject to the agreements of the JS7 - License.
Cluster Management
The architecture applies to the clustering of two Controller instances acting as a passive cluster:
- Controller instances synchronize order state information and perform fail-over (automated) and switch-over (by user intervention).
- There is no need for use of an active cluster that aims at scalability: a single Controller instance offers unlimited scalability.
There are situations when cluster members need an arbitrator to decide which member should take the active role:
- If both Controller instances are shutdown and are restarted then the previously active instance cannot know if in between the standby instance was active. It is pointless to rely on operating system timestamps to clarify this situation.
- If a Controller instance continues to run but is isolated in the network in a way that no network connection can be established by the partner instance then this situation requires an arbitrator.
The role of the arbitrator is to act as a Cluster Watch and to add a vote in situations for which Controller instances cannot decide about the active role.
- The Cluster Watch is connected to both Controller instances and keeps track of cluster events.
- If the active Controller instance cannot be reached then the Cluster Watch is consulted by the standby Controller instance to decide if fail-over should be performed.
- A Controller Cluster works fine without a Cluster Watch during normal operation, however, for start-up of Controller instances and for fail-over the Cluster Watch is required.
The Cluster Watch role is available from JOC Cockpit and alternatively from an Agent:
- It is generally recommended to use JOC Cockpit as Cluster Watch as this provides high availability and fail-over of the Cluster Watch role if a JOC Cockpit Cluster is used.
- In a scenario when a number of Controller instances are managed by JOC Cockpit users might tend to use individual Agents acting as Cluster Watch per Controller.
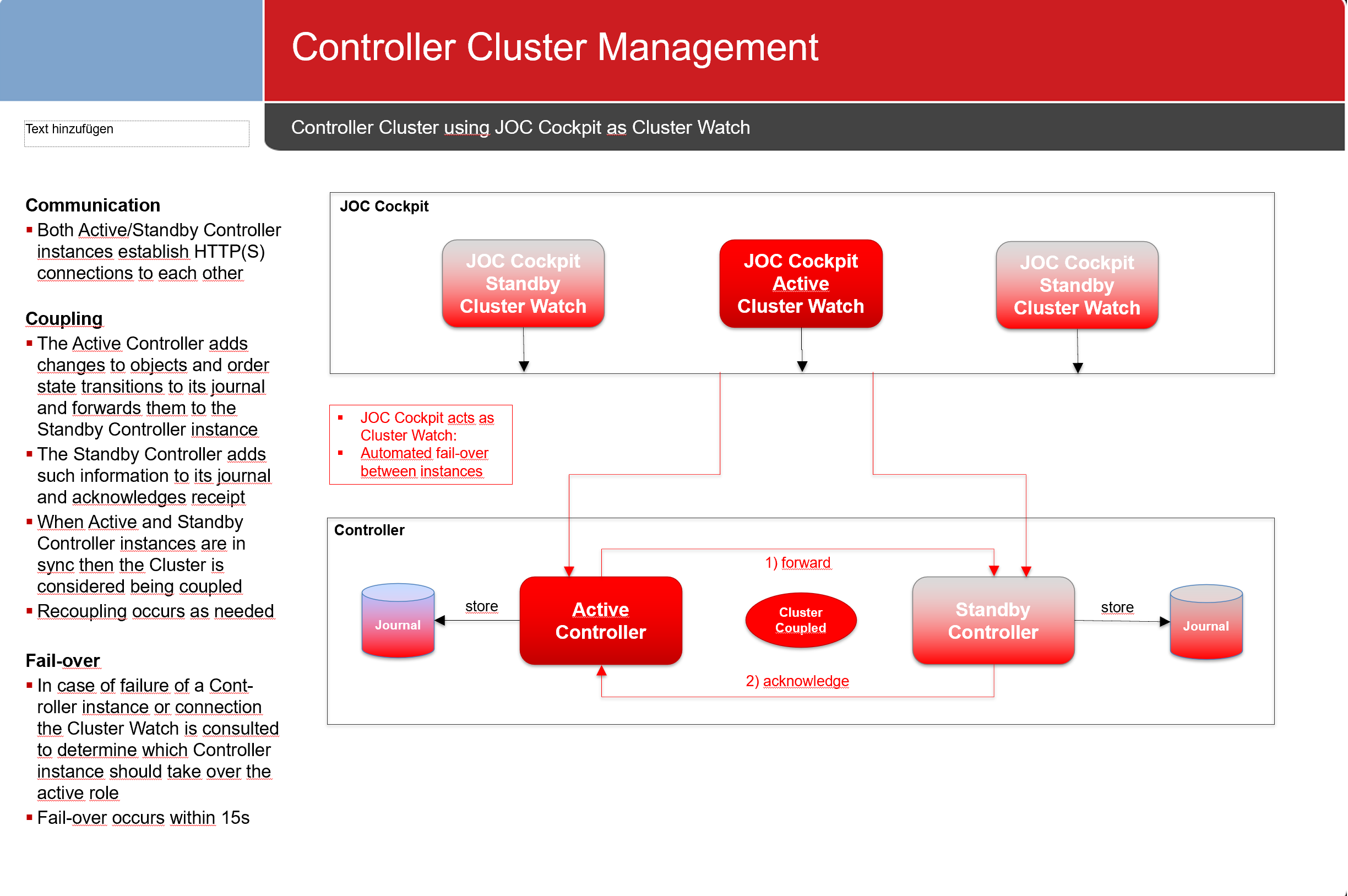
Using JOC Cockpit as Cluster Watch
Any number of JOC Cockpit instances can act as Cluster Watch to determine the active Controller instance.
- Network connections are established from the active JOC Cockpit instance to the Controller.
- This scenario offers high availability for the JOC Cockpit instance acting as a Cluster Watch.
- In case of switch-over or fail-over in a JOC Cockpit Cluster the next available JOC Cockpit instance will take the active role and will act as a Cluster Watch.
- Should both Controller Cluster and JOC Cockpit Cluster fail-over at the same time then the user has to decide about the active Controller instance. In this situation JOC Cockpit displays an alarm bell and the user has to check and to confirm that the current standby Controller instance is not up and running.
- FEATURE AVAILABILITY STARTING FROM RELEASE 2.5.2
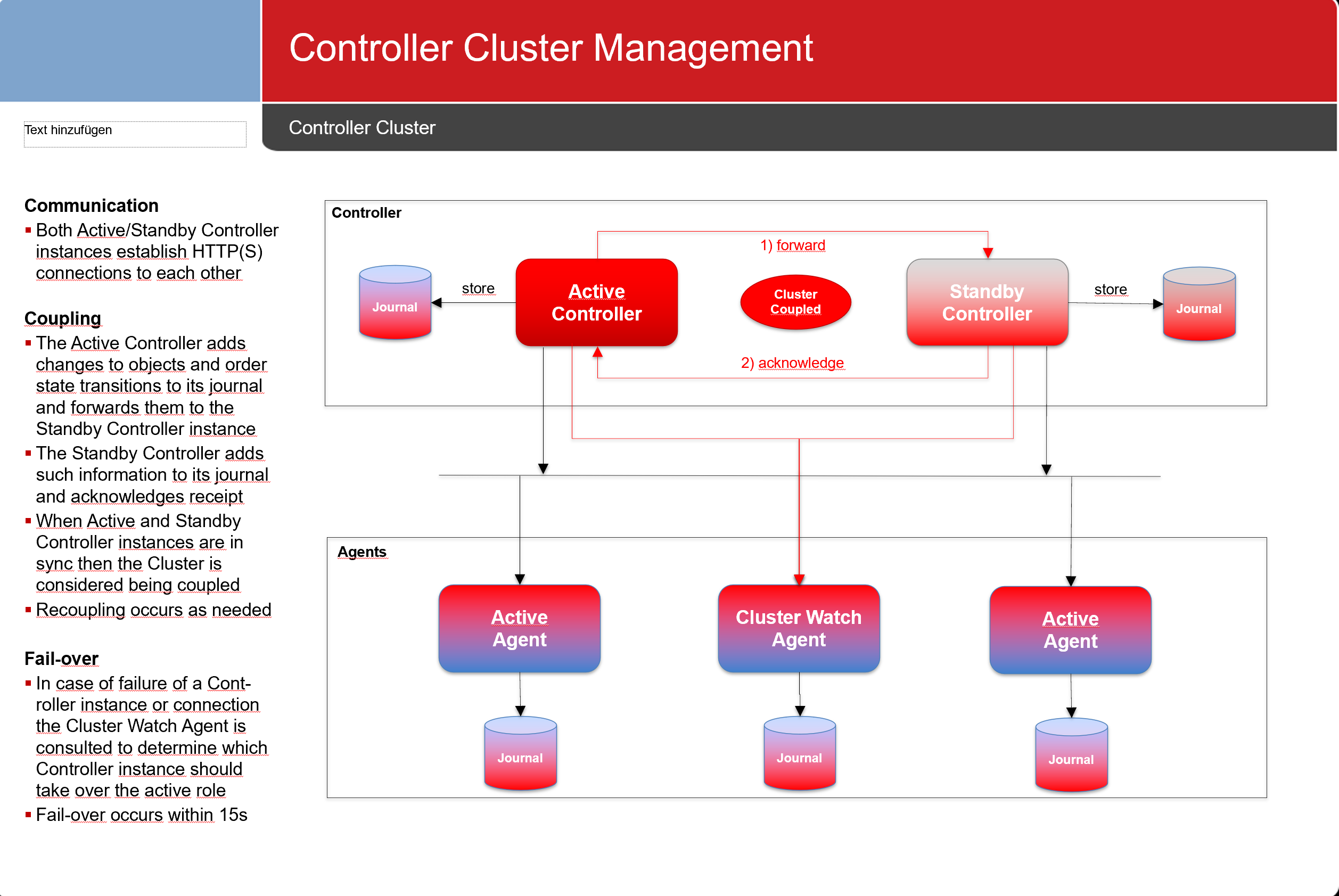
Using an Agent as Cluster Watch
A single Cluster Watch Agent can be used to determine the active Controller instance.
- Network connections are established from both Controller instances to the Cluster Watch Agent.
- This scenario does not offer high availability for the Agent acting as a Cluster Watch.
- The Cluster Watch Agent is required to be available at the point in time when a Controller Cluster fail-over should occur.
- FEATURE AVAILABILITY ENDING WITH RELEASE 2.6.0
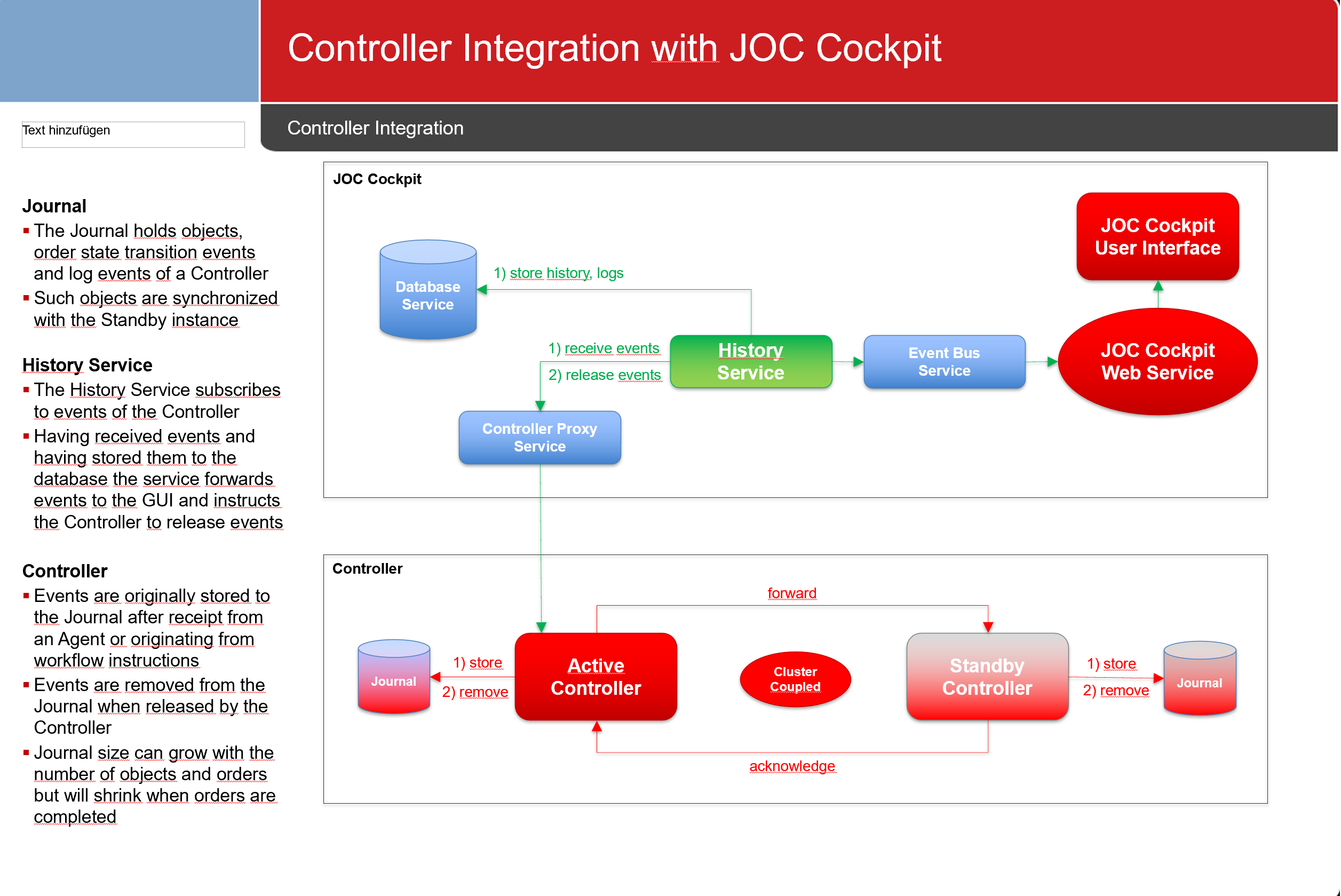
Integration with JOC Cockpit
A single JOC Cockpit instance or a JOC Cockpit Cluster can be used to connect to a Controller:
- JOC Cockpit makes use of the built-in Proxy Service to connect to the Controller. This includes automatically switching the active Controller instance in the case of fail-over or switch-over of a Controller.
- JOC Cockpit receives state information from a Controller that is added to the history, for example log events, and that is visualized in the GUI (order state events).
Network Connections
Network connections use the HTTP protocol and can be secured by TLS/SSL certificates.
Connections are:
- bidirectional between Controller instances,
- unidirectional from JOC Cockpit to Controller instances.
For details consider the JS7 - System Architecture.
Cluster Fail-over Scenarios
Fail-over occurs automatically as opposed to switch-over which is triggered by user intervention.
Fail-over does not occur in case of normal shutdown of a Controller instance as this does not indicate failure, but for example a maintenance interval. Consider that normal shutdown without fail-over similarly applies for server shutdown
- of Unix systems if JS7 - systemd Service Files for automated Startup and Shutdown with Unix Systems are used.
- of Window systems if Windows Services are used to operate JS7 products.
Subsequently the term unavailability is used. This indicates a number of situations:
- The Controller instance is crashed, is killed or the underlying machine is crashed.
- The Controller instance continues to run but is isolated in the network which means that the paring Controller instance and active JOC Cockpit instance cannot connect to the instance. Network isolation can be a tricky source of fail-over if this occurs for a short period only.
Unavailability of a Controller Instance
This scenario includes situations when a single Controller instance or the underlying machine become unavailable.
- If the active Controller instance becomes unavailable then the standby Controller instance and the active JOC Cockpit Cluster Watch will determine to perform fail-over within a few seconds.
- If the standby Controller instance becomes unavailable then the active Controller instance will continue to run without changes.
- If a previously unavailable (as opposed to shutdown) Controller instance is started after fail-over then it will take the standby role in the Controller Cluster. It will synchronize its journal from the active Controller instance and will re-establish the cluster.
Unavailability of a Controller instance and JOC Cockpit instance
This scenario includes situations when a single Controller instance and a single JOC Cockpit instance running on the same or different machine become unavailable.
- If the active Controller instance and active JOC Cockpit instance become unavailable at the same point in time then
- first the standby JOC Cockpit instance will become active. This includes that the Cluster Watch role will move to this instance. Fail-over of JOC Cockpit will take <30s. There can be a slightly longer duration in case that we find a larger number of orders that have not been completed and for which the newly active JOC Cockpit instance has to re-read state transition events and log events from the remaining Controller instance. Observations include that 500 orders with maybe 2000 jobs can delay fail-over by approx. 60s.
- next the newly active JOC Cockpit instance and the standby Controller instance agree on fail-over and the standby Controller instance becomes active within a few seconds.
- If the standby Controller instance and standby JOC Cockpit instance become unavailable then this does not affect the active Controller instance and active JOC Cockpit instance.
Unavailability of both Controller instances and both JOC Cockpit instances
This scenario includes a situation when any machines holding a Controller instance and JOC Cockpit instance become unavailable at the same point in time.
- This situation can be considered a disaster as all redundant nodes are gone at the same point in time. This situation requires user intervention.
- Reasons are as follows:
- When the previously active Controller instance is started then it remembers having had this role and will ask the JOC Cockpit Cluster Watch for confirmation.
- The newly started JOC Cockpit instance with the Cluster Watch role cannot confirm the Controller's request as it has no memory before the point in time of unavailability and does not know which Controller instance had the active role before the unavailability occurred. The Cluster Watch cannot confirm the claim of any Controller instance to become active as this claim can be wrong. For example, if a Controller instance crashed some days earlier and in between fail-over occurred to the then standby Controller instance. If in this situation both Controller instances are (re)started then the JOC Cockpit Cluster Watch can determine the Controller instance with the active role as it was a witness to the respective Controller instance's last crash or shutdown.
- In this scenario if any machines die at the same time there is no fail-over between JOC Cockpit instances. This means that the Cluster Watch cannot act as an arbitrator and instead has to ask the user for confirmation. JOC Cockpit will show a red alarm bell to indicate that user intervention is required.
- User confirmation includes to consent that one of the Controller instances that is suggested by the JOC Cockpit Cluster Watch should be considered being lost. The remaining Controller instance will take the active role.
- Before confirming users should check that the Controller instance to be declared lost in fact is shutdown.
- If this check is missed and if the lost Controller instance in fact is up & running and considers itself to have the active role then this can cause both Controller instances to become active and can result in double job execution. As a consequence the Controller Cluster has to be recreated and Agents have to be initialized.
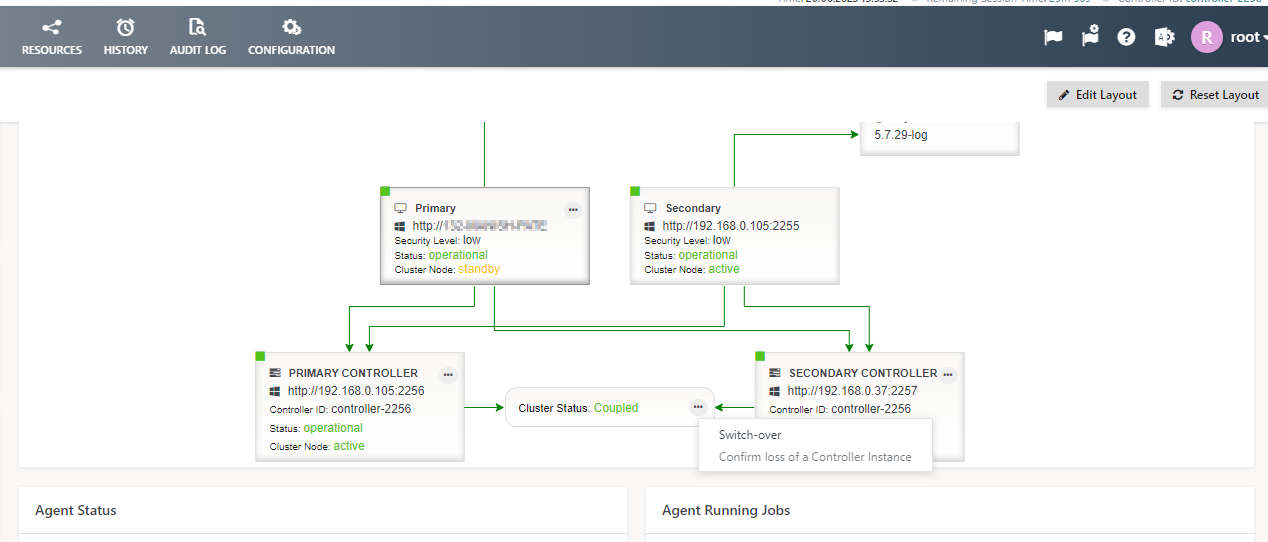
- Users confirm loss of the indicated Controller instance from the Dashboard view like this:
Further Resources
Overview
Content Tools