Page History
...
- Fail-over is an automated operation that occurs when the Primary Controller is aborted or killed. Fail-over is applied in case of abnormal termination, see JS7 - Impact of a Controller outage.
- Switch-over is an operation that is caused by user intervention in JOC Cockpit or by use of the JS7 - REST Web Service API. The switch-over procedure does not require termination of an Active Controller Instance, instead it shifts the active role to the second standby Controller instance.
For fail-over and switch-over a dedicated Standalone Agent acting as a the role of the Cluster Watch Agent is required that acts as an arbitrator in situations when the Controller Cluster cannot determine about the active instance. Either JOC Cockpit or an Agent can be assigned the Cluster Watch role.
For command line references see the JS7 - Controller - Command Line Operation article.
...
- The terms Active Controller Instance and Standby Controller Instance are often more significant, regardless of whether it is the Primary or Secondary Controller Instance which is active.
- A Controller implements an active-passive cluster, however, the term passive is misleading as the Standby Controller Instance is not passive at all but records any order state transitions occurring in the Active Controller Instance. Both Controller instances hold a journal of order state transitions that is actively synchronized. Fail-over and switch-over will occur only if both Controller instances' journals are in sync.
- The Cluster presents itself as a single unit to the outside world, i.e. to JOC Cockpit and to Agents.
- Any operations performed in JOC Cockpit are automatically applied to the Active Controller Instance.
- At any point in time only one Controller instance is active and the other instance is in standby mode.
Cluster Watch
...
Role
Primary and Secondary Controller instances require a dedicated Standalone Agent to be available that acts JOC Cockpit or an Agent to act as Cluster Watch, i.e. as an arbitrator in case of fail-over and switch-over.
Start-up of Controller Cluster
Connections
- If JOC Cockpit is acting as Cluster
...
- Watch then JOC Cockpit will establish a connection on start-up of Primary and Secondary Controller instances.
- If an Agent is acting as Cluster Watch then on start-up both Primary and Secondary Controller instances will establish a connection to the Cluster Watch Agent.
Proceeding
- The Cluster Watch Agentcasts its vote which Controller instance owns the leading journal.
- Start-up of a Controller Cluster is not possible with the Cluster Watch Agentbeing unavailable.
- Start-up of the previously Active Controller Instance without the Standby Controller Instance being available is possible if the Cluster Watch Agentis active.
Failure of the Active Controller Instance
In case of failure of the Active Controller Instance the Cluster Watch Agent plays plays its role as an arbitrator:
- The Cluster Watch Agent knows knows immediately when the Active Controller Instance is down due to a connection loss from this instance.
- The Standby Controller Instance holds a connection to the Active Controller Instance and knows immediately when this connection is lost.
- Failure of the Active Controller Instance is the point in time when the Standby Controller Instance and the Cluster Watch Agentcheck to find common ground about a cluster fail-over operation: They determine if they should declare the Active Controller Instance being inoperable and after a short period of 1-2s they proceed and cast their votes if the Standby Controller Instance should now become the Active Controller Instance.
- As a prerequisite for fail-over both the Cluster Watch Agentand the Standby Controller Instance have to confirm that the Standby Controller Instance's journal was in sync with the Active Controller Instance at the point in time of failure.
Operation of Cluster Watch
Cluster Watch
- If JOC Cockpit is assigned the Cluster Watch
...
- role then fail-over capabilities of JOC Cockpit apply.
- If an Agent is assigned the Cluster Watch role then the above explanations suggest that
...
- the Agent should never be run on the hosts that the Primary and Secondary Controller instances are operated on.
Proceeding
- If the Cluster Watch Agent is is terminated at the same time as a failed Active Controller Instance then no fail-over can occur.
- If the Cluster Watch Agentis terminated at the same time as one of the Controller instances then the Controller Cluster cannot start up as this requires operational readiness of the Cluster Watch Agent.
- A Cluster Watch Agentthat is started after failure of the Active Controller Instance is disqualified from casting its vote as it has no knowledge of whether the Controller instances' journals are in sync.
...
- The Active Controller Instance is killed, for example:
- on Unix with a SIGKILL signal corresponding to the command:
kill -9 - on Windows with the command:
taskkill /F
- on Unix with a SIGKILL signal corresponding to the command:
- The operating system crashes.
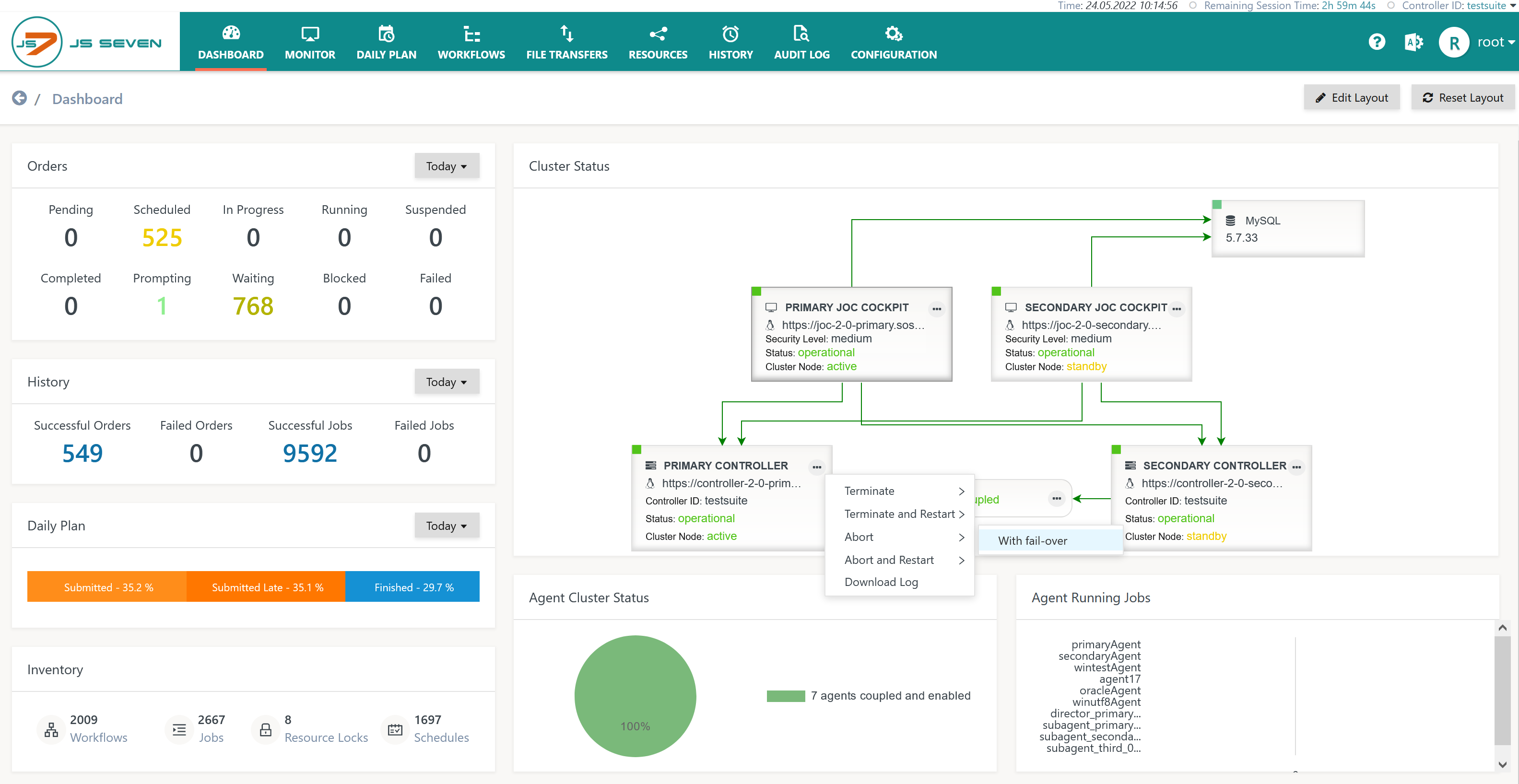
- In the JS7 - Dashboard the user performs one of the operations:
- Active Controller Instance action menu: Abort -> With fail-over
- Active Controller Instance action menu:Abort and restart -> With fail-over
- From the command line the user performs one of the operations:
controller.sh | .cmd abortcontroller.sh | .cmd kill
...
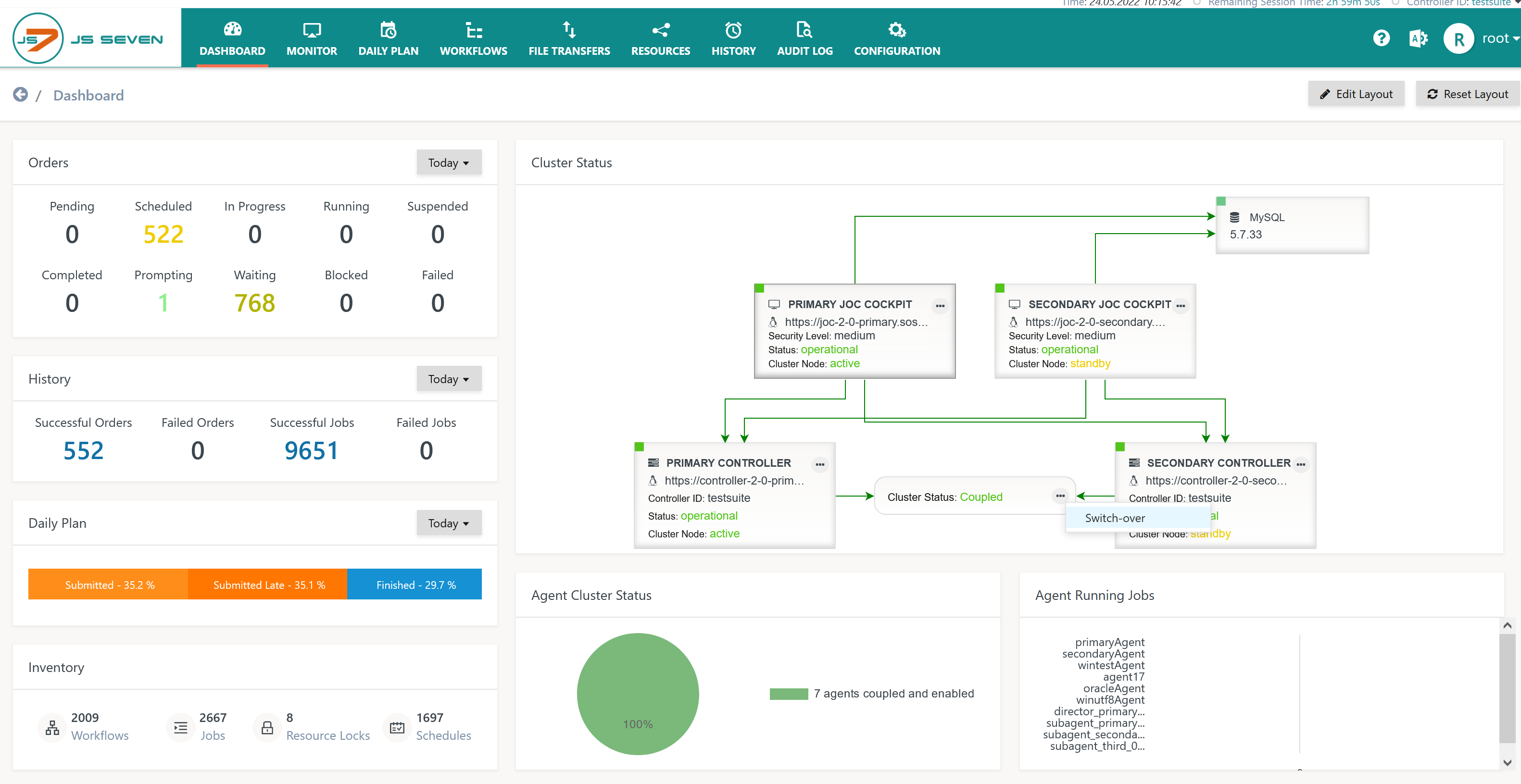
- In the JS7 - Dashboard the user performs one of the operations:
- Active Controller Instance action menu: Terminate -> With switch-over
- Active Controller Instance action menu:Terminate and restart -> With switch-over
- Cluster action menu: Switch-over
Switch-over will not occur when:
...
- The cluster has to guarantee that only one of both Standalone Controller instances is started at any point in time.
- If this rule is not observed then both Controller instances will instruct Agents to execute the same workflows and jobs which will can result in double job execution.
- Controller journals will be messed up with the same orders in different state transitions.
- In this situation the only solution is to drop both Controller instances' journals that are available from the
statesub-directory, to accept that any orders are lost and to redeploy scheduling objects.
- There is no simple way to determine if a Controller instance is not in perfect condition to manage orders.
- Performing PID file checks is of limited use: this can prove the unavailability of a Controller instance. However, a positive PID file check does not prove that a Controller instance is working.
- Log file analysis is pointless. Controllers heavily make use of asynchronous operations when it comes to Agents. Occurrence of error messages in log files includes allowing a situation to be recovered within the next few secondsmilliseconds.
- A Controller Cluster guarantees high availability when used with a JS7 - Agent Cluster. Use of Standalone Agents limits high availability.
...
Overview
Content Tools